Recuperação de Servidores Dell, HPE, SuperMicro, IBM, Lenovo
🚨 Luzes de alerta piscando (vermelhas ou âmbar)?
🖥️ Sistema operacional não inicia (Tela Azul / Kernel Panic)?
📁 Arquivos, bancos de dados ou máquinas virtuais inacessíveis?
A E-Recovery tem avaliação 4.9 / 5.0 no Google ⭐⭐⭐⭐⭐

Recuperar Dados de Servidores?
Para recuperar servidores RAID, o primeiro passo é identificar o tipo de falha — física (em um ou mais discos) ou lógica (corrupção do sistema de arquivos).
Em falhas físicas, recomenda-se isolar o servidor, substituir os discos danificados e evitar qualquer tentativa de reinicialização para não sobrescrever dados. Nas falhas lógicas, é necessário reconstruir virtualmente o array RAID para restaurar a estrutura original.
A E-Recovery é especialista em recuperação de dados de servidores RAID, com tecnologia avançada e ambiente seguro para lidar com falhas complexas, garantindo a máxima integridade e confidencialidade das informações corporativas.
Veja o que NÃO fazer para piorar a situação!
Uma falha de servidor é o pior pesadelo de um departamento de TI. Um servidor Dell PowerEdge, HPE ProLiant ou Supermicro parado não significa apenas arquivos perdidos; significa que toda a operação da empresa está offline: bancos de dados (SQL, Oracle), sistemas ERP/CRM e todas as Máquinas Virtuais (VMs).
A sua primeira reação pode ser tentar “consertar” o problema rapidamente. Cuidado. Em um ambiente de servidor, a ação errada pode transformar uma falha recuperável em uma perda de dados permanente. Siga estas orientações críticas:
🚫 NÃO FORCE O ARRAY (RAID) ONLINE – Se o servidor reiniciar e a controladora RAID (ex: Dell PERC, HPE Smart Array) acusar um disco como “Failed” (Falho) ou “Foreign Configuration” (Configuração Estrangeira), NÃO tente “Forçar Online” (Force Online) ou “Importar” (Import) o disco. Se o disco estiver “obsoleto” (stale) devido a uma falha anterior, forçá-lo a voltar ao array irá corromper matematicamente 100% dos seus dados.
💻 NÃO RODE O CHKDSK OU FSCK – Se o volume (partição) do servidor aparece como “RAW” ou “Corrompido”, rodar uma verificação de disco (chkdsk no Windows Server, fsck no Linux) é uma armadilha. Essas ferramentas foram feitas para consertar erros, não para salvar dados. Elas podem “consertar” a corrupção apagando os metadados dos seus arquivos e VMs, tornando a recuperação impossível.
📞 DESLIGUE O SERVIDOR E CONTATE NOSSOS ESPECIALISTAS – Se os dados são críticos, a única ação 100% segura é desligar o servidor (especialmente se houver barulhos de clique) e contatar um especialista. Oferecemos diagnóstico gratuito para identificar a falha (seja ela nos discos, na controladora ou lógica) e a viabilidade da recuperação, sem compromisso.
Especialistas nas Marcas Líderes de Servidores do Mercado

Especialistas nas Principais Marcas de Servidores
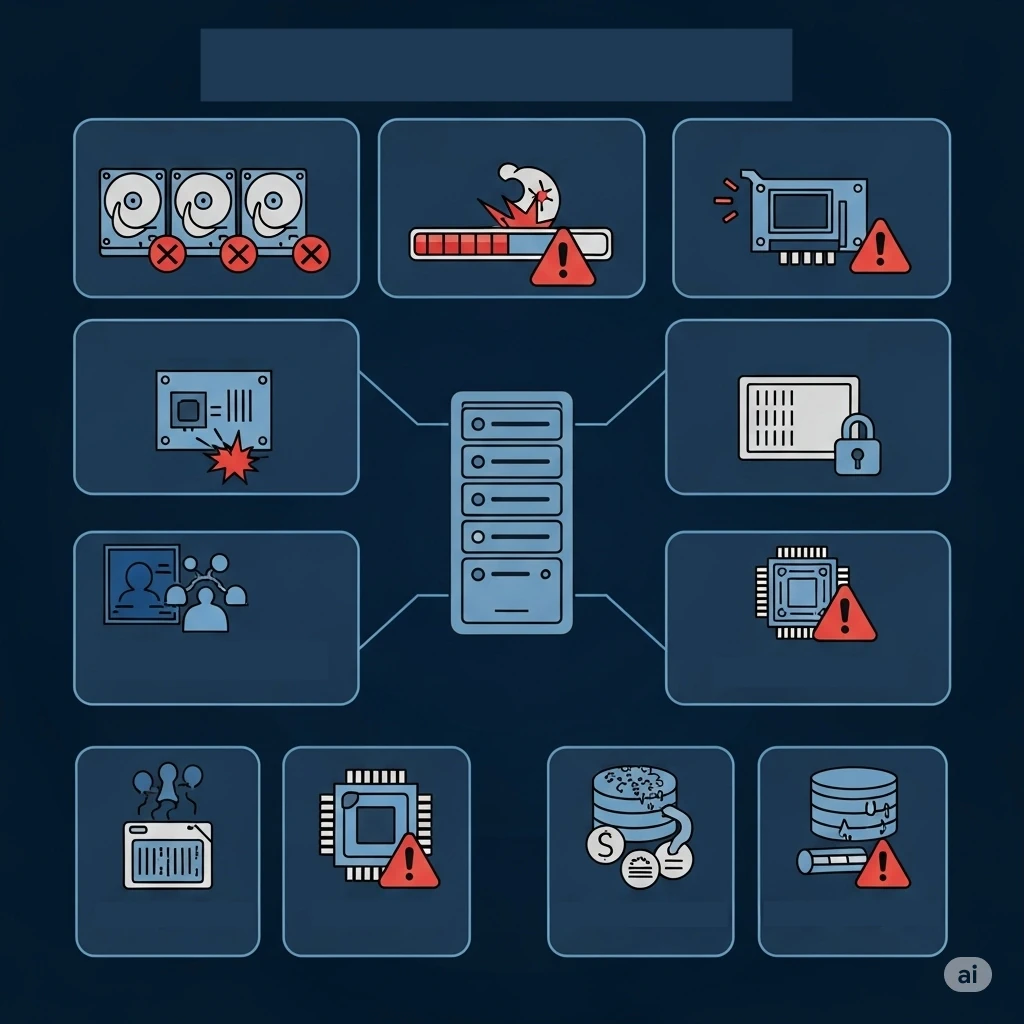
Veja os problemas mais comuns em servidores RAID que solucionamos diariamente:
Recuperação de Servidor Dell (PowerEdge, PERC)
Seu servidor Dell PowerEdge parou? A controladora PERC acusa “Foreign Configuration”? Não importe a configuração! Somos especialistas em recuperar arrays RAID de controladoras Dell PERC. O seu servidor Dell (PowerEdge, PowerVault) está apresentando algum destes sintomas?
- 🚨 Erro “Foreign Configuration” – O servidor reiniciou (após queda de energia) e a controladora PERC (H310, H710, H730, etc.) não “monta” o RAID, exibindo uma mensagem de “Foreign configuration found” (Configuração estrangeira encontrada).
- 🚫 Múltiplos Discos “Failed” ou “Offline” – O painel LCD do servidor (ou o iDRAC) está âmbar, mostrando que 2 ou mais discos falharam em um RAID 5 ou 6.
- 🖥️ “No Boot Device Found” – O servidor não encontra mais o “disco” (o array) onde o sistema operacional (Windows Server, VMware) estava instalado.
- 🧩 Metadados Corrompidos – A controladora “esqueceu” a configuração do RAID e os discos (que estão bons) aparecem como “Ready” (Prontos) para criar um novo array.
Entendendo a Falha do Servidor Dell (A Armadilha da PERC)
Os servidores Dell PowerEdge usam a controladora PERC (PowerEdge RAID Controller) para gerenciar o array. Essa placa é o “cérebro” que armazena a “receita” (metadados) do seu RAID (ordem dos discos, tamanho do bloco, paridade, etc.).
Quando ocorre uma falha (queda de energia, 2 discos falham em um RAID 5), a controladora “perde” essa receita ou detecta discos “obsoletos” (stale). Para se proteger, ela marca os discos como “Foreign” (Estrangeiros) e oferece ao administrador a opção de “Importar” ou “Limpar” (Clear) a configuração. É aqui que o desastre acontece.
⚠️ A REGRA DE OURO: NÃO “IMPORTE” E NÃO “LIMPE” UMA “FOREIGN CONFIGURATION”!
A sua primeira reação de TI será acessar a BIOS da PERC (Ctrl+R) e clicar em “Import Foreign Configuration”. NÃO FAÇA ISSO!
Se um dos discos estiver “stale” (obsoleto, com dados de 1 dia atrás) e você “importar”, a controladora pode usar esse disco antigo para corromper a paridade do array inteiro, destruindo permanentemente 100% dos dados. Da mesma forma, NUNCA clique em “Clear Configuration” (Limpar Configuração), pois isso apaga a “receita” do RAID dos discos, tornando a recuperação muito mais difícil.
Perguntas Frequentes (FAQ): Recuperação de Servidor Dell
1. Quais modelos de Servidor Dell vocês recuperam? Nós temos expertise em todas as linhas de servidores e storages da Dell e Dell EMC. Os mais comuns que chegam ao laboratório incluem:
- Servidores em Torre (PowerEdge T-Series): Dell PowerEdge T110, T130, T140, T310, T320, T330, T340, T410, T420, T430, T440, T610, T620, T630, T640, e gerações mais novas.
- Servidores em Rack (PowerEdge R-Series): Dell PowerEdge R210, R220, R230, R240, R310, R320, R330, R340, R410, R420, R430, R440, R510, R520, R530, R540, R610, R620, R630, R640, R710, R720, R730, R740, e gerações mais novas.
- Storages (PowerVault MD/ME): Dell PowerVault MD (ex: MD3000, MD3200i, MD3400) e ME (ex: ME4012, ME4024).
- Controladoras: Qualquer servidor usando controladoras Dell PERC (ex: H310, H330, H700, H710, H730, H740, H750) ou SAS HBA.
2. O que significa “Foreign Configuration” (Configuração Estrangeira)? Significa que a controladora PERC está “vendo” discos que contêm uma configuração de RAID, mas essa configuração não bate com o que ela tem na memória. É um modo de segurança. O problema é que a opção de “Import” é uma aposta: se os discos estiverem “obsoletos” (stale) após um rebuild falho, a importação destrói os dados.
3. Minha controladora PERC (a placa física) queimou. Posso comprar outra “idêntica” no Mercado Livre e trocar? É extremamente arriscado. Se a placa nova tiver uma versão de firmware (software interno) diferente da sua placa antiga, ela pode não ler a “receita” do RAID corretamente ou tentar “atualizar” os metadados nos discos, corrompendo o array. A única recuperação 100% segura é feita sem a controladora original.
4. O iDRAC (módulo de gerenciamento) está mostrando 2 discos “Failed” em um RAID 5. O que fazer? Desligue o servidor. O RAID 5 só tolera a falha de 1 disco. Se 2 falharam, o array está “morto”. A recuperação exige a clonagem de todos os discos (incluindo os falhos) e a remontagem virtual do array.
5. Como a E-Recovery recupera um array de uma PERC? Nós não precisamos da sua placa PERC. Nosso processo é 100% mais seguro:
- Clonagem: Clonamos (bit-a-bit) todos os discos do seu array PowerEdge (os bons e os falhos).
- Reparo (Sala Limpa): Os discos que falharam fisicamente (se houver) são reparados em Sala Limpa.
- Engenharia Reversa: Usamos um “simulador de RAID” forense para analisar os clones. Nosso software faz a “engenharia reversa” dos metadados específicos da PERC gravados nos discos.
- Remontagem Virtual: Descobrimos a “receita” exata (ordem, bloco, paridade, disco “stale”) e remontamos o seu RAID 5, 6 ou 10 virtualmente.
- Extração: O volume (com suas VMs, banco de dados SQL, etc.) reaparece, e nós extraímos seus dados intactos.
Recuperação de Servidor HPE (ProLiant, Smart Array)
Seu servidor HPE ProLiant não “dá boot”? A controladora Smart Array acusa falha de “accelerator battery”? Não desabilite o cache! Somos especialistas em falhas de controladoras HPE Smart Array e iLO.
O seu servidor HPE (ProLiant, StoreVirtual) está apresentando algum destes sintomas?
- 🚨 Luz Vermelha Piscando – O “Health LED” (luz de saúde) no painel frontal do servidor (especialmente em modelos ProLiant DL/ML) está piscando em vermelho ou âmbar.
- POST Error 1783 / 1720 – O servidor para na tela de inicialização (POST) com um erro de “Drive Array Failure” (Falha no Array de Discos) ou “Smart Array controller failure”.
- 🔋 Falha na Bateria (Cache) – Um erro comum: “Array accelerator battery failure” (Falha na bateria do acelerador). O controlador (Smart Array P410, P420, P440) desativa o cache de gravação e, às vezes, “derruba” o array para proteger os dados.
- 🚫 Múltiplos Discos “Failed” – A interface de gerenciamento (iLO – Integrated Lights-Out) ou o Array Configuration Utility (ACU) mostra 2 ou mais discos falhos em um RAID 5 ou 6.
Entendendo a Falha do Servidor HPE (A Armadilha da Bateria de Cache)
Os servidores HPE ProLiant são conhecidos por sua robustez e pela controladora HPE Smart Array. Uma das principais causas de falha (além da falha de múltiplos discos) é a falha da bateria de cache (FBWC – Flash-Backed Write Cache).
Essa bateria protege os dados que estão temporariamente na memória da controladora (cache) em caso de queda de energia. Quando essa bateria (ou capacitor) falha, a controladora entra em pânico. Ela não sabe se os dados no cache foram gravados nos discos. Para se proteger, ela pode se recusar a “montar” o array RAID, deixando o servidor “preso” no boot (ex: Erro 1783).
⚠️ A REGRA DE OURO: NÃO TENTE “FORÇAR” O ARRAY ONLINE OU “DESABILITAR O CACHE”!
Se o seu servidor parou por uma falha na bateria do acelerador (Cache), a sua primeira reação de TI será entrar na BIOS da Smart Array e “Desabilitar o Cache” (Disable Cache) ou “Forçar Online” (Force Online) o array. NÃO FAÇA ISSO SEM UM BACKUP!
Se havia dados “presos” no cache que não foram gravados nos discos, “forçar” o array a montar sem esse cache pode causar uma corrupção lógica catastrófica no seu sistema de arquivos, banco de dados ou máquinas virtuais (VMs).
Perguntas Frequentes (FAQ): Recuperação de Servidor HPE
1. Quais modelos de Servidor HPE vocês recuperam? Nós temos expertise em todas as linhas de servidores e storages da HPE (Hewlett Packard Enterprise) e da HP antiga. Os mais comuns que chegam ao laboratório incluem:
- Servidores em Torre (ML): HPE ProLiant ML30, ML110, ML350 (G6, G8, G9, G10).
- Servidores em Rack (DL): HPE ProLiant DL360, DL380, DL385 (G6, G8, G9, G10).
- Sistemas Blade (BL): Servidores Blade da série BL.
- Storages (MSA): HPE MSA 1000, 2000 Series (P2000, 2040, 2050, 2060).
2. O que é o erro “Array Accelerator Battery Failure” e por que ele “quebra” o RAID? O “Array Accelerator” é o cache de escrita da sua controladora Smart Array. Ele usa uma bateria (FBWC) ou um capacitor (FSA) para proteger os dados no cache se a energia cair. Quando essa bateria “morre” (geralmente após 3-4 anos), a controladora não tem mais proteção. Para evitar a perda de dados, ela se recusa a aceitar novas gravações e, por segurança, pode “derrubar” o array inteiro até que a bateria seja trocada e os dados do cache sejam validados.
3. O iLO (gerenciamento) está mostrando 2 discos falhos em um RAID 5. O que fazer? Desligue o servidor. O RAID 5 só tolera a falha de 1 disco. Se 2 falharam, o array está “morto”. A recuperação exige a clonagem de todos os discos (incluindo os falhos) e a remontagem virtual do array. (Veja nosso FAQ de RAID 5 para detalhes).
4. Como a E-Recovery recupera um array de uma Smart Array (HPE)? Nós não precisamos da sua controladora Smart Array. Nosso processo é 100% mais seguro:
- Clonagem: Clonamos (bit-a-bit) todos os discos do seu array ProLiant.
- Reparo (Sala Limpa): Os discos que falharam fisicamente (se houver) são reparados em Sala Limpa.
- Engenharia Reversa: Usamos um “simulador de RAID” forense para analisar os clones. Nosso software faz a “engenharia reversa” dos metadados específicos da HPE Smart Array (que são diferentes dos da Dell PERC) gravados nos discos.
- Remontagem Virtual: Descobrimos a “receita” exata (ordem, bloco, paridade) e remontamos o seu RAID 5, 6 ou 10 virtualmente.
- Extração: O volume (com suas VMs, banco de dados, etc.) reaparece, e nós extraímos seus dados intactos.
Recuperação de Servidor Supermicro (SuperServer, LSI/Broadcom)
Seu servidor Supermicro (SuperServer) não “dá boot”? A controladora (LSI/Broadcom) falhou? Não recrie o array! Somos especialistas em falhas de servidores Supermicro e controladoras LSI/Adaptec. O seu servidor Supermicro está apresentando algum destes sintomas?
- 🚫 “No Boot Device Found” – O servidor liga, passa pela tela de inicialização (POST), mas não encontra o sistema operacional (Windows Server, Linux, VMware).
- 🚨 Luzes de Alerta Piscando – Luzes de falha de disco (vermelhas ou âmbar) estão acesas no painel frontal ou nas baias dos HDs.
- 🧩 RAID “Offline” ou “Missing” – A BIOS da controladora RAID (ex: LSI/Broadcom MegaRAID ou Adaptec) mostra o array (Virtual Drive) como “Offline”, “Failed” ou “Missing”.
- 🖥️ Servidor “Travado” no POST – O servidor trava na tela de inicialização, geralmente ao tentar “ler” a controladora RAID (ex: “Initializing LSI MegaRAID…”).
Entendendo a Falha do Servidor Supermicro (O Risco da Flexibilidade)
Servidores Supermicro (SuperServer) são a escolha de data centers e empresas que buscam performance e flexibilidade. Por não usarem hardware proprietário, eles geralmente combinam placas-mãe Supermicro com controladoras RAID de alta performance (como LSI/Broadcom MegaRAID ou Adaptec) ou usam Software RAID (como ZFS ou Linux mdadm).
A falha ocorre quando a controladora (hardware) falha, corrompe seus metadados (a “receita” do RAID) ou quando múltiplos discos falham (ex: 2 discos em RAID 5), quebrando o array.
⚠️ A REGRA DE OURO: NÃO TENTE “IMPORTAR” OU “RECRIAR” O ARRAY NA BIOS DA CONTROLADORA!
A primeira reação de TI será entrar na BIOS da controladora (ex: Ctrl+H ou Ctrl+R) e tentar “Importar Configuração Estrangeira” (Import Foreign) ou “Recriar” (Rebuild/Re-create) o array. NÃO FAÇA ISSO!
“Importar” um array com discos “stale” (obsoletos) pode corromper a paridade. “Recriar” o array APAGA os metadados e formata os discos, destruindo os dados permanentemente. Desligue o servidor.
Perguntas Frequentes (FAQ): Recuperação de Servidor Supermicro
1. Quais modelos de Servidor Supermicro vocês recuperam? Nós temos expertise em todas as linhas de servidores Supermicro, incluindo:
- Servidores em Rack (Ultra, Twin): SuperServer 1U e 2U (Ex: 6029P, 1029P, 2029P).
- Servidores de Alta Densidade (FatTwin): Modelos FatTwin 2U/4U.
- Servidores Torre (SuperWorkstation): (Ex: 7049A, 5039A).
- Storages (SuperStorage): Modelos JBOD, ZFS ou de alta capacidade (StorageBridges).
- Controladoras: Qualquer servidor usando controladoras LSI/Broadcom (MegaRAID 92xx, 93xx) ou Adaptec.
2. A controladora LSI/Broadcom do meu Supermicro queimou. Posso trocar por outra? É extremamente arriscado. Se a placa nova (mesmo sendo o “mesmo” modelo) tiver uma versão de firmware (software interno) diferente, ela pode não ler a “receita” do RAID ou tentar “atualizá-la”, corrompendo o array. A recuperação 100% segura é feita sem a controladora original.
3. O servidor está travado na tela de “Initializing” da LSI/Adaptec. O que é isso? Este é um sintoma clássico de falha. Significa que a controladora está tentando ler os discos (para encontrar o array) e não está conseguindo. A causa pode ser um disco falho que está “travando” o barramento SAS/SATA, ou a própria controladora está com o firmware corrompido. Desligue o servidor para evitar danos.
4. Como a E-Recovery recupera um array de um Supermicro? Nós não precisamos da sua controladora LSI ou Adaptec. Nosso processo é 100% forense:
- Clonagem: Clonamos (bit-a-bit) todos os discos do seu array.
- Reparo (Sala Limpa): Discos com falha física (cliques) são reparados em Sala Limpa.
- Engenharia Reversa: Usamos um “simulador de RAID” forense para analisar os clones e fazer a “engenharia reversa” dos metadados específicos da sua controladora (LSI, Broadcom, Adaptec).
- Remontagem Virtual: Descobrimos a “receita” exata (ordem, bloco, paridade) e remontamos o seu RAID 5, 6 ou 10 virtualmente.
- Extração: O volume (com suas VMs, banco de dados, etc.) reaparece, e nós extraímos seus dados intactos.
Recuperação de Servidor IBM (System x, ServeRAID)
Seu servidor IBM (System x, BladeCenter) parou? A controladora ServeRAID acusa “Defunct” (Extinto)? Não recrie o array! Somos especialistas em falhas de controladoras IBM ServeRAID e System x. O seu servidor IBM está apresentando algum destes sintomas?
- 🚨 Luz de Alerta Âmbar (Laranja) – O painel frontal (light path diagnostics) está indicando uma falha de disco (Drive Fault) ou de RAID.
- 🚫 Array “Defunct” ou “Offline” – A BIOS da controladora ServeRAID (ex: M5015) mostra o seu “Logical Drive” (array) como “Defunct” (Extinto) ou “Offline”.
- 💾 “Missing Configuration” – O servidor reiniciou (após queda de energia) e a controladora “esqueceu” a configuração do RAID, mostrando os discos como “Unconfigured Good”.
- 🖥️ Servidor “Preso” no Boot – O sistema trava na tela de inicialização, ao tentar carregar a BIOS da controladora ServeRAID ou LSI.
Entendendo a Falha do Servidor IBM (A Armadilha da ServeRAID)
Os servidores IBM da linha System x são conhecidos pela sua robustez e pelo uso de controladoras poderosas, como a série IBM ServeRAID (que muitas vezes são baseadas em LSI/Broadcom, mas com firmware customizado).
A falha ocorre quando a controladora (hardware) falha, corrompe sua memória (NVRAM) ou, o mais comum, quando múltiplos discos falham em um RAID 5 (quebrando o array). O termo “Defunct” é a forma da IBM dizer que o array está “morto” (geralmente por falha de 2 discos em RAID 5, ou falha de um par em RAID 10).
⚠️ A REGRA DE OURO: NÃO “LIMPE” (CLEAR) A CONFIGURAÇÃO OU “RECRIE” O ARRAY!
Se a sua controladora ServeRAID mostra o array como “Defunct” ou os discos como “Unconfigured” (Não configurados), a sua primeira reação de TI será tentar “Recriar” (Re-create) o array com os mesmos discos ou “Limpar” (Clear) a configuração. NÃO FAÇA ISSO!
“Limpar” a configuração apaga a “receita” do RAID (metadados) dos discos. “Recriar” o array formata os discos e zera os metadados, destruindo permanentemente a chance de recuperação. Desligue o servidor.
Perguntas Frequentes (FAQ): Recuperação de Servidor IBM
1. Quais modelos de Servidor IBM vocês recuperam? Nós temos expertise em todas as linhas de servidores IBM, especialmente as que usam a arquitetura x86 (que agora são da Lenovo), incluindo:
- Servidores em Torre (System x): IBM System x3100 (M4, M5), x3300, x3500 (M4, M5).
- Servidores em Rack (System x): IBM System x3530, x3550 (M4, M5), x3650 (M4, M5).
- Sistemas Blade: IBM BladeCenter (HS22, HS23, etc.).
- Storages: IBM System Storage (DS e Storwize).
- Controladoras: Qualquer servidor usando controladoras IBM ServeRAID (ex: M1015, M5015, M5110) ou LSI.
2. A minha controladora ServeRAID queimou. Posso trocar por outra? É extremamente arriscado. Como as controladoras da IBM são frequentemente LSI “rebatizadas” com firmware customizado, se a placa nova (mesmo sendo o “mesmo” modelo) tiver uma versão de firmware diferente, ela pode não ler a “receita” do RAID ou tentar “atualizá-la”, corrompendo o array. A recuperação 100% segura é feita sem a controladora original.
3. O que significa “Array Defunct”? Significa “extinto” ou “falido”. É o termo da ServeRAID para um array que falhou catastroficamente (ex: 2 discos falharam em RAID 5, ou 3 em RAID 6). O array não pode ser “forçado online” e os dados estão inacessíveis.
4. Como a E-Recovery recupera um array de uma ServeRAID? Nós não precisamos da sua controladora ServeRAID. Nosso processo é 100% forense:
- Clonagem: Clonamos (bit-a-bit) todos os discos do seu array System x.
- Reparo (Sala Limpa): Discos com falha física (cliques) são reparados em Sala Limpa.
- Engenharia Reversa: Usamos um “simulador de RAID” forense para analisar os clones e fazer a “engenharia reversa” dos metadados específicos da IBM/LSI gravados nos discos.
- Remontagem Virtual: Descobrimos a “receita” exata (ordem, bloco, paridade) e remontamos o seu RAID 5, 6 ou 10 virtualmente.
- Extração: O volume (com suas VMs, banco de dados, etc.) reaparece, e nós extraímos seus dados intactos.
Recuperação de Servidor Lenovo (ThinkSystem, System x)
Seu servidor Lenovo ThinkSystem (ou System x) está offline? O XClarity reporta falha de disco? Não “Inicialize” o RAID! Somos especialistas em recuperar arrays RAID de servidores Lenovo.
O seu servidor Lenovo (ThinkSystem, ThinkServer, System x) está apresentando algum destes sintomas?
- 🚨 Luz de Alerta Laranja (Âmbar) – O painel frontal do servidor está indicando uma falha de disco ou de RAID.
- 🚫 RAID “Inoperante” (Inoperative) – O Gerenciador de RAID (XClarity, LSI, etc.) mostra o “Virtual Drive” (array) como “Inoperante” ou “Failed”.
- 🖥️ Erro 1801 / 1805 – O servidor para no boot com erros como “Erro 1801: Configuração de RAID Incompatível” ou “Erro 1805: Falha no Array RAID”.
- 🧩 “Foreign Configuration” – A controladora detectou os discos, mas os marca como “Configuração Estrangeira” (Foreign Configuration) e não consegue “Importar” (Import).
Entendendo a Falha do Servidor Lenovo (A Herança da IBM)
A Lenovo comprou a divisão de servidores x86 da IBM em 2014, continuando a linha System x e lançando a nova e poderosa linha ThinkSystem. Por causa dessa herança, os servidores Lenovo usam controladoras de altíssima performance (geralmente LSI/Broadcom MegaRAID ou controladoras “onboard” da Intel em modelos de entrada).
A falha é idêntica à de outros grandes servidores: perda de múltiplos discos em um RAID 5 (superando a paridade), falha da controladora (hardware), ou corrupção de metadados após uma queda de energia.
⚠️ A REGRA DE OURO: NÃO “IMPORTE” A CONFIGURAÇÃO ESTRANGEIRA (FOREIGN CONFIGURATION)!
Assim como nas controladoras Dell PERC, se o seu servidor Lenovo (especialmente com uma controladora LSI/Broadcom) detectar os discos como “Foreign” (Estrangeiros), NÃO use a opção “Import Foreign Configuration” (Importar Configuração Estrangeira) sem ter um backup completo.
Se um dos discos estiver “stale” (obsoleto, com dados de 1 dia atrás) e você “importar”, a controladora pode usar esse disco antigo para corromper a paridade do array inteiro, destruindo permanentemente 100% dos dados.
Perguntas Frequentes (FAQ): Recuperação de Servidor Lenovo
1. Quais modelos de Servidor Lenovo vocês recuperam? Nós temos expertise em todas as linhas de servidores Lenovo, desde a herança da IBM até os mais modernos:
- Servidores em Torre (ThinkSystem ST / ThinkServer TS): Lenovo ST50, ST250, ST550, ST650 V2; e os antigos ThinkServer TS140, TS440.
- Servidores em Rack (ThinkSystem SR / System x): Lenovo SR250, SR550, SR630, SR650; e os legados System x (ex: x3650 M5, x3550 M5).
- Controladoras: Qualquer servidor usando controladoras Lenovo RAID (ex: 530, 730, 930 series), LSI/Broadcom MegaRAID, ou Intel VROC.
2. O XClarity Controller (o “iDRAC” da Lenovo) mostra 2 discos falhos em RAID 5. O que fazer? Desligue o servidor. O RAID 5 só tolera a falha de 1 disco. Se 2 falharam, o array está “morto”. A recuperação exige a clonagem de todos os discos (incluindo os falhos) e a remontagem virtual do array.
3. Qual a diferença entre recuperar um IBM System x e um Lenovo System x? Tecnicamente, quase nenhuma. A “receita” (metadados) do RAID gravada nos discos pela controladora LSI/ServeRAID é a mesma. Nossa engenharia reversa funciona em ambos. A diferença está no hardware (a placa-mãe e o gerenciador, como o IMM da IBM ou o XClarity da Lenovo), do qual nós não precisamos para recuperar os dados.
4. Como a E-Recovery recupera um array de um Lenovo? Nós não precisamos da sua controladora RAID. Nosso processo é 100% forense:
- Clonagem: Clonamos (bit-a-bit) todos os discos do seu array ThinkSystem.
- Reparo (Sala Limpa): Discos com falha física (cliques) são reparados em Sala Limpa.
- Engenharia Reversa: Usamos um “simulador de RAID” forense para analisar os clones e fazer a “engenharia reversa” dos metadados específicos da Lenovo/LSI/Broadcom gravados nos discos.
- Remontagem Virtual: Descobrimos a “receita” exata (ordem, bloco, paridade) e remontamos o seu RAID 5, 6 ou 10 virtualmente.
- Extração: O volume (com suas VMs, banco de dados, etc.) reaparece, e nós extraímos seus dados intactos.
Recuperação de Máquinas Virtuais (VMware, Hyper-V, Xen)
Seu Datastore (VMFS) está “Offline” ou “Inacessível”? Suas VMs (VMDK/VHDX) sumiram? Não tente “recriar” o datastore! Somos especialistas em recuperar ambientes virtuais complexos. O seu ambiente de virtualização está apresentando algum destes sintomas?
- 🚫 Datastore Inacessível (VMFS/CSV) – O host VMware ESXi/vSphere não “vê” mais o Datastore, ou o cluster Hyper-V mostra o “Volume Compartilhado Clusterizado” (CSV) como “Offline”.
- 📂 Arquivos .VMDK / .VHDX Sumiram – A pasta do datastore está vazia, os arquivos das VMs (os “discos rígidos virtuais”) desapareceram ou o datastore aparece como “Não Formatado” (RAW).
- ❌ VM “Corrompida” – A Máquina Virtual não liga e dá um erro de “arquivo não encontrado”, “disco corrompido” ou “a cadeia de snapshots está quebrada”.
- 🧩 “LUN” Perdida – O Storage (Dell, HPE, etc.) “perdeu” a LUN (o disco virtual) que continha o datastore, geralmente após uma falha de RAID.
Entendendo a Falha de Virtualização (A Dupla Camada)
A perda de dados em um servidor virtualizado é um desastre de duas camadas:
- Camada de Hardware (O RAID): Primeiro, o hardware falha. O seu RAID 5 (com 2 discos falhos), RAID 6 (com 3 discos falhos) ou sua controladora (PERC, Smart Array) quebra.
- Camada Lógica (O Datastore): O volume (LUN) que estava “em cima” desse RAID quebrado agora está inacessível. O VMware (que usa um sistema de arquivos especial chamado VMFS) ou o Hyper-V (que usa NTFS/CSV) não consegue mais “montar” esse volume.
Seus arquivos de VM (.VMDK, .VHDX) estão, na verdade, “fatiados” pelo RAID e “presos” dentro de um sistema de arquivos (VMFS) que está “quebrado”.
⚠️ A REGRA DE OURO: NÃO TENTE “RECRIAR” O DATASTORE (VMFS)!
Quando um Datastore VMFS desaparece, a primeira reação de um administrador de TI é usar o vSphere para “Criar um novo Datastore” no LUN que parece estar vazio. NÃO FAÇA ISSO JAMAIS!
Isso formata o LUN e apaga os metadados (o “mapa”) do VMFS original, destruindo os ponteiros para todos os seus arquivos .VMDK. Esta ação zera as chances de recuperação. Da mesma forma, não rode vmfs-tools ou fsck em um volume instável.
Perguntas Frequentes (FAQ): Recuperação de Máquinas Virtuais
1. Quais sistemas de virtualização vocês recuperam? Nós temos expertise em todas as principais plataformas de virtualização do mercado, incluindo:
- VMware: ESXi, vSphere, vSAN (com sistemas de arquivos VMFS 3, 5 e 6).
- Microsoft: Hyper-V (em Windows Server 2012, 2016, 2019, 2022) e seus Volumes Compartilhados Clusterizados (CSV).
- Citrix: XenServer / Hypervisor.
- Linux/Open Source: Proxmox, KVM, Oracle VM, VirtualBox.
2. O RAID falhou. A recuperação das VMs é diferente de uma recuperação de arquivos normal? Sim, muito. Em uma recuperação de arquivos normal, procuramos por “JPGs” ou “DOCs”. Em uma recuperação de VM, nós procuramos pelos arquivos de disco virtual (ex: NomeDaVM-flat.vmdk ou NomeDaVM.vhdx) e pelos arquivos de snapshot. Nosso objetivo não é recuperar “arquivinhos”, mas sim a Máquina Virtual inteira e funcional.
3. O meu datastore VMFS está “Inacessível”. É um problema do VMware ou do RAID? Quase sempre é um sintoma de um problema no RAID. O VMFS é muito robusto, mas ele depende 100% do hardware (o RAID) abaixo dele. Se o RAID falha (ex: 2 discos em RAID 5), o VMFS “quebra” junto.
4. Como a E-Recovery recupera minhas VMs? (O Estudo de Caso da USP) Nosso processo é uma recuperação de “múltiplas camadas”, exatamente como fizemos para a USP (onde recuperamos 100% de 10 VMs após uma falha de 2 discos em RAID 5).
- Clonagem: Clonamos (bit-a-bit) todos os discos do servidor.
- Remontagem do RAID: Fazemos a engenharia reversa da controladora (PERC, Smart Array, LSI) para remontar virtualmente o seu RAID 5, 6, 10, etc.
- Reparo do Datastore: No RAID virtual, usamos software forense para reparar o sistema de arquivos VMFS ou NTFS/CSV e localizar os ponteiros dos discos virtuais.
- Extração dos Arquivos VM: Extraímos os arquivos .VMDK / .VHDX intactos (e seus snapshots), prontos para você “importar” em um novo servidor e voltar à produção.
Recuperação de Banco de Dados (SQL, MySQL, Oracle)
Seu Banco de Dados (SQL Server, MySQL) está “Corrompido”, “Suspect” ou “Offline”? Não tente o “Recovery Mode”! Somos especialistas em reparar arquivos MDF/LDF e bancos de dados corrompidos.
O seu servidor de Banco de Dados (Database Server) está apresentando algum destes sintomas?
- ❌ Banco “Suspect” (Suspeito) – O seu Microsoft SQL Server não consegue “montar” o banco. Ele aparece como “Suspect” (Suspeito) ou “Recovery Pending” (Recuperação Pendente).
- 📄 Arquivo .MDF/.LDF Corrompido – O arquivo de dados principal (.mdf) ou o arquivo de log (.ldf) está danificado, ilegível ou foi deletado, e o banco de dados não sobe.
- 💾 Falha de RAID – O servidor (Dell, HPE, etc.) que hospedava o banco de dados falhou (ex: 2 discos em RAID 5), e agora o arquivo do banco está inacessível.
- 🚫 Tabelas “Quebradas” (MySQL/MariaDB) – O seu banco de dados (MySQL, MariaDB) está reportando tabelas “quebradas” (crashed) ou corrompidas (ex: “InnoDB corruption”).
Entendendo a Falha do Banco de Dados (A Corrupção Lógica)
A recuperação de um Banco de Dados é um dos serviços mais delicados. Na maioria das vezes, o hardware (o RAID) falhou primeiro. Uma queda de energia ou a falha de um disco corrompeu a gravação que estava aconteCendo exatamente no arquivo do banco de dados (ex: .mdf).
O resultado é uma corrupção lógica grave. O RAID pode até voltar (após a troca de um disco), mas o arquivo do banco de dados está “quebrado” por dentro. Ele tem “meia informação” gravada, e o sistema (SQL, MySQL) não sabe como lidar com isso e se recusa a iniciar.
⚠️ A REGRA DE OURO: NÃO RODE COMANDOS DE REPARO (REPAIR_ALLOW_DATA_LOSS)!
Quando um banco SQL está “Suspect”, a internet (e até mesmo a Microsoft) sugere que você execute comandos como DBCC CHECKDB com a opção REPAIR_ALLOW_DATA_LOSS (Reparar Permitindo Perda de Dados).
NÃO FAÇA ISSO JAMAIS! Esse comando é uma “bomba atômica”. Ele “conserta” o banco deletando permanentemente todas as páginas de dados que ele não consegue ler. Você pode até conseguir fazer o banco “subir”, mas ele estará cheio de “buracos”: tabelas inteiras podem sumir, dados de clientes podem desaparecer, e a integridade do banco é destruída.
Perguntas Frequentes (FAQ): Recuperação de Banco de Dados
1. Quais bancos de dados vocês recuperam? Nós temos expertise em todas as principais plataformas de banco de dados do mercado, incluindo:
- Microsoft: SQL Server (arquivos .MDF, .LDF, .NDF).
- MySQL / MariaDB: (arquivos .IBD, .FRM, .MYI).
- Oracle: (arquivos .DBF, .ORA).
- Outros: PostgreSQL, Firebird, e bancos de dados legados (como dBase, FoxPro, etc.).
2. O RAID 5 do meu servidor falhou. A recuperação do banco SQL é um processo separado? Sim. É um processo de duas etapas:
- Etapa 1 (Recuperar o RAID): Primeiro, nós remontamos virtualmente o seu RAID 5 (Dell PERC, HPE Smart Array, etc.) para recuperar os arquivos “grandes”.
- Etapa 2 (Recuperar o Banco): Em seguida, nós pegamos o arquivo .mdf (SQL) ou .dbf (Oracle) recuperado e, se ele estiver corrompido (o que é comum após uma falha de RAID), nós usamos ferramentas forenses de reparo de banco de dados para reconstruir as tabelas e índices.
3. O que significa um banco SQL “Suspect” (Suspeito)? Significa que o SQL Server tentou iniciar o banco, encontrou uma inconsistência grave (corrupção) e, por segurança, “desistiu” de montá-lo. A causa quase sempre é uma falha de hardware (o RAID) ou uma queda de energia.
4. Como a E-Recovery recupera um banco de dados .MDF corrompido? Nós nunca usamos o comando REPAIR_ALLOW_DATA_LOSS.
- Clonagem: Criamos uma cópia (clone) do seu arquivo .MDF / .LDF.
- Análise de Baixo Nível: Usamos ferramentas forenses especializadas em SQL/MySQL/Oracle.
- Leitura de Páginas: Nosso software lê o arquivo “página por página” (blocos de 8KB, no caso do SQL), “pulando” as páginas corrompidas e reconstruindo a estrutura das tabelas.
- Extração de Dados: Extraímos todos os dados recuperáveis (tabelas, procedures, views) para um novo banco de dados saudável (um novo arquivo .mdf ou um script SQL), garantindo a máxima integridade dos dados que não foram danificados.
Por que Empresas e Departamentos de TI Confiam na E-Recovery
ACOMPANHAMENTO
Cada caso de servidor é atribuído a um especialista dedicado, que será seu ponto de contato único durante todo o processo de recuperação de dados. Nós mantemos você informado de cada etapa da recuperação de forma pró-ativa. Você não precisa ligar para saber o que está acontecendo. Nós o manteremos informado a cada etapa concluída para te manter atualizado.
ESPECIALIZAÇÃO
Nós não vendemos peças e nem damos manutenção em computadores. Somos 100% focados e especializados em recuperação de dados. Essa dedicação total garante um nível de conhecimento e equipamentos que só um laboratório especializado pode oferecer, resultando em um índice de sucesso muito superior.
ATENDIMENTO 24X7
Sabemos que um servidor parado significa prejuízo. Por isso, casos de servidores recebem status de emergência e prioridade máxima em nosso laboratório. Nosso processo é desenhado para ser o mais ágil possível, desde o diagnóstico até a entrega dos dados, para que sua empresa volte a operar no menor tempo imaginável.
SEM DADOS, SEM CUSTOS
Para a maioria dos casos, você só realiza o pagamento após a validação de que os dados essenciais para a sua empresa foram recuperados com sucesso. Se, por qualquer motivo, não conseguirmos recuperar os arquivos que você precisa, não haverá nenhum custo pelo serviço de recuperação. O risco é todo nosso.
CONFIDENCIALIDADE
A segurança dos seus dados é nossa prioridade máxima. Assinamos um Acordo de Confidencialidade (NDA) em todos os serviços, garantindo o sigilo total das suas informações. Nossos processos são executados em redes isoladas e seguras, e nossa equipe é composta por profissionais rigorosamente selecionados. Seus dados estão protegidos conosco.
TRANSPARÊNCIA
Oferecemos um diagnóstico completo e sem compromisso ou emergencial, detalhando as causas da falha, a lista de arquivos recuperáveis (se possível) e as chances de sucesso. Com base nisso, apresentamos um orçamento fixo e detalhado. Você saberá o valor exato do investimento antes de aprovar o serviço, sem surpresas ou custos ocultos.

Como Funciona o Processo?
Veja como funciona o processo de recuperação de dados, do começo ao fim, com total clareza e sem surpresas.
Contato Inicial e Entrega do Dispositivo
Entre em contato conosco pelo formulário, WhatsApp ou telefone. Você pode entregar seu dispositivo em qualquer uma de nossas unidades:
- Matriz (Vila Mariana)
- Unidades de Recebimento (Barra Funda, Pinheiros, Morumbi ou Tatuapé)
- Você também pode enviá-lo via Correios ou transportadora.
Importante: Lembre-se de embalar muito bem seu dispositivo em plástico bolha e uma caixa segura para protegê-lo durante o transporte.
Diagnóstico e Orçamento
Realizaremos uma análise completa do seu HD ou SSD para identificar o problema e a viabilidade da recuperação. Você receberá uma proposta comercial detalhada por e-mail, dentro da modalidade de urgência que você escolher. O valor da análise é cobrado por dispositivo:
Avaliação Emergencial (8 horas corridas): R$ 400,00
Avaliação Expressa (24 horas corridas): R$ 200,00
Avaliação Gratuita (48 horas úteis): R$ 0,00
Observação Importante: Para casos de alta complexidade, como Servidores com sistemas RAID ou ambientes de virtualização (VMware, Hyper-V, etc.), estes valores de avaliação poderão sofrer acréscimos. Qualquer alteração será informada e aprovada por você antes do início da análise.
Recuperação em Laboratório
O serviço de recuperação dos seus dados só é iniciado após a sua aprovação formal do orçamento. Nossos especialistas utilizarão os equipamentos e técnicas necessárias para extrair seus dados com segurança em nosso laboratório (na matriz).
Validação dos Dados Recuperados
Esta é a etapa mais importante para você. Assim que o trabalho for concluído, enviaremos a lista de arquivos. Você mesmo fará a validação através de um acesso remoto (via Anydesk ou UltraViewer) para abrir e testar seus arquivos mais importantes.
Pagamento do Serviço
A regra “No Data, No Charge” (Sem Dados, Sem Cobrança” se aplica para a grande maioria dos casos. O pagamento do serviço de recuperação só é efetuado após você aprovar o resultado. Mas existem exceções.
Nossa Política de Risco Compartilhado (Leia com Atenção):
Para cobrir a alocação de recursos, tempo de especialista e investimentos, alguns serviços mais complexos e demorados exigem uma taxa inicial (de análise, engajamento ou investimento em peças), paga independentemente do resultado final. Isso inclui:
- Avaliação Expressa e Emergencial.
- Casos de Ransomware.
- Dispositivos formatados ou com dados deletados.
- CD, DVD ou Blu-Ray.
- Discos muito danificados.
- Serviços que exigem a compra de peças (ex: HD doador).
- Projetos de alta complexidade (ex: Servidores RAID, volumes de dados muito grandes).
Qualquer taxa deste tipo será sempre detalhada em sua proposta comercial antes da sua aprovação.
Entrega e Retirada dos Dados
Após a aprovação e o pagamento, seus dados recuperados serão preparados para a entrega:
- Cópia em Mídia Física (Sem Custo Adicional): Você pode nos fornecer um HD ou SSD novo, e faremos a cópia dos dados recuperados sem custo adicional de gravação.
- Entrega via Nuvem (Tarifado): A devolução dos dados via nuvem (Google Drive ou One Drive) é um serviço adicional e envolve custos extras, que serão detalhados em sua proposta.
Local de Retirada: Por questões de segurança, a retirada do seu dispositivo original e da nova mídia com os dados é feita exclusivamente em nossa matriz, na Vila Mariana.
Encerramento e Apagamento Seguro dos Dados
Para garantir sua total privacidade e segurança, temos uma política de apagamento de dados rigorosa. Após a entrega dos seus dados recuperados, manteremos uma cópia de segurança em nossos servidores por um período de 7 (sete) dias corridos.
Após este prazo, a cópia é permanentemente excluída de nossos sistemas e o serviço é considerado totalmente encerrado. Por isso, é fundamental que você confira seus arquivos e faça seu próprio backup assim que recebê-los.
O Que Gerentes de TI Falam sobre a E-Recovery
Grandes empresas confiam na E-Recovery, você também pode confiar!


Depoimento do sr. Cardoso da Gráfica de Segurança Formflex (Carapicuíba/SP) referente recuperação de dados de um NAS Seagate configurado com RAID 5.
Depoimento de Christian Uhlmann sobre um NAS QNAP configurado em RAID 1 que ficou subitamente inacessível pela rede, causado por dois discos danificados
“Excelente profissionalismo da empresa. Tive problemas de queda de energia onde danificaram alguns HDs e desmontou todo o Array do RAID. Falei que precisava com urgência dos dados, o Sr. Orlando juntamente com sua equipe se prontificou de imediato, e deu uma atenção excepcional, atendendo todas as minhas expectativas. Negociei os valores também, explicando nossa (empresa) situação. E o mesmo nós ajudou também com a parte financeira. Excelente empresa e profissionais.”
Fernando Andrade Ulhôa, gerente de TI do Comitê Paralímpico Brasileiro
Estudo de Caso: Falha de RAID 5 em Servidor Dell Pós-Queda de Energia
O Cliente: Comitê Paralímpico Brasileiro / Fernando Andrade Ulhôa
O Desafio (O Problema): O Comitê Paralímpico Brasileiro enfrentou um cenário de desastre em seu data center: uma queda de energia causou danos físicos em múltiplos discos de um Servidor Dell configurado com 7 HDs em RAID 5.
O resultado foi uma falha catastrófica: o evento “desmontou todo o Array do RAID”, tornando todos os dados do servidor inacessíveis. O Comitê precisava dos dados com urgência para a continuidade de suas operações.
A Solução (O Processo da E-Recovery): O cliente nos contatou e, entendendo a urgência, nossa equipe se prontificou de imediato. A recuperação de um RAID 5 com múltiplos discos danificados fisicamente exige um processo de alta complexidade:
Diagnóstico e Reparo: Os 7 HDs passaram por diagnóstico. Os discos fisicamente danificados (pela queda de energia) foram levados à Sala Limpa para reparo e estabilização.
Clonagem Forense: Todos os 7 discos foram clonados (bit-a-bit) para mídias saudáveis.
Engenharia Reversa (RAID 5): Nossos engenheiros analisaram os clones para identificar os parâmetros do RAID (ordem dos discos, paridade, tamanho do bloco) e identificar quais discos estavam “obsoletos” (stale) devido à falha.
Remontagem Virtual: O array RAID 5 foi reconstruído virtualmente em nossos servidores, usando a paridade dos discos bons para “recriar” os dados dos discos falhos.
O Resultado (Sucesso Total): Conseguimos recuperar os dados críticos do Comitê, atendendo à demanda de urgência e validando a confiança depositada em nossa equipe.
Não arrisque seus dados. Fale com um especialista em Servidores agora!
O tempo é crucial. Quanto mais rápido você agir, maiores as chances de recuperação. Preencha o formulário abaixo para um diagnóstico e orçamento gratuitos ou chame-nos no WhatsApp.
Endereço:
Av Professor Noé de Avevedo 208 cj 65 - Vila Mariana - São Paulo/SP - CEP 04117-000
Telefone / WhatsApp
Voz: (11) 3422-0066
WhatsApp: (11) 93075-5919
contato@e-recovery.com.br
FORMULÁRIO DE SOLICITAÇÃO DE ORÇAMENTO:

Dúvidas Gerais sobre a Recuperação de Servidor
Veja as perguntas mais comuns sobre recuperação de dados de RAID. Se a sua dúvida for outra, entre em contato com nossa equipe de atendimento.
O diagnóstico para um Servidor (Dell, HPE, IBM) é gratuito?
Sim, 100% gratuito e sem compromisso paara orçamentos feito no prazo normal. Entendemos que uma falha de servidor é um evento crítico. Nossos especialistas farão uma análise completa de todos os discos para identificar a falha (seja ela nos discos, na controladora RAID ou lógica/VMs) e o potencial de recuperação. Você receberá um laudo técnico e um orçamento fixo antes de qualquer serviço.
E se meus dados não puderem ser recuperados? Eu pago mesmo assim?
Nossa política “Sem Dados, Sem Custo” (No Data, No Fee) é válida para a grande maioria dos casos, EXCETO volumes formatados, dados deletados, ataque de ransomware, HDs com necessidade de investimento em peças ou servidores com muitos discos ou volumes de grande capacidade.
Eu preciso enviar o Servidor (gabinete, rack) inteiro?
NÃO. Envie APENAS OS DISCOS (HDs/SSDs). Nós não precisamos do seu hardware (o chassi do PowerEdge, ProLiant, etc.). Nosso laboratório possui controladoras e equipamentos forenses próprios para remontar todos os tipos de RAID.
A ordem dos discos dento do servidor importa?
SIM! ESTE É O PASSO MAIS IMPORTANTE! Antes de remover os discos, use uma fita crepe ou caneta de retroprojetor e numere a ordem exata em que eles estavam nas baias do servidor (ex: Disco 0, Disco 1, Disco 2, Disco 3…). Enviar os discos fora de ordem pode atrasar o diagnóstico (ou, em casos raros, inviabilizar a recuperação).
Quanto tempo demora a recuperação de um Servidor?
Entendemos que um servidor parado significa prejuízo. Casos de Servidor/RAID têm prioridade máxima em nosso laboratório.
Diagnóstico: Concluído em até 24 horas úteis.
Problemas Lógicos/Firmware: (Ex: RAID 5 com 2 discos falhos, “Foreign Configuration”, VMs corrompidas). Geralmente de 2 a 5 dias úteis.
Problemas Físicos (Ex: 1+ Disco Clicando): Pode levar de 5 a 10 dias úteis. Precisamos primeiro reparar os discos falhos em Sala Limpa (um processo de “transplante”) para depois cloná-los e remontar o RAID.
Meu servidor rodava Máquinas Virtuais (VMware/Hyper-V). Vocês recuperam as VMs?
Sim. Essa é a nossa especialidade. Não recuperamos apenas “arquivos”; nós recuperamos sistemas inteiros. Nosso processo inclui a reconstrução do datastore (como VMFS, no caso do VMware) e a extração dos arquivos de máquina virtual (VMDK, VHDX) intactos, prontos para serem “importados” em um novo servidor
Como eu recebo meus dados de volta?
Nós nunca gravamos os dados de volta no seu array de discos original (ele está danificado e instável). Os dados recuperados (suas VMs, bancos de dados, etc.) são salvos em uma mídia nova (geralmente um novo HD externo de grande capacidade), que você deverá fornecer.