Av. Prof. Noé de Azevedo, 208 cj. 65 (11) 3422-0066 contato@e-recovery.com.br
Recuperar RAID: Diagnóstico Gratuito e Atendimento Emergencial 24/7
Recuperação de RAID com volumes offline, degradado ou com falha na controladora. Somos especialistas em recuperar dados de RAID 0, 1, 5, 6, 10 e 50 em servidores Dell, HP, Lenovo e Storages NAS. Não inicie o rebuild. Nota 4.9 no Google , +8.200 casos, 20 anos de experiência.
Atendemos todo Brasil via Sedex ou recuperação remota.
Precisa Recuperar RAID Array com Algum Desses Problemas?
RAID "Degraded"
Um ou mais discos falharam. O array opera no limite — qualquer nova falha derruba tudo.
"Foreign Configuration"
A controladora perdeu os metadados e não reconhece mais o array original.
Volume RAW
O sistema pede formatação ou a partição simplesmente desapareceu.
Discos Offline Simultâneos
Dois ou mais HDs pararam ao mesmo tempo, quebrando a paridade e bloqueando o volume.
Rebuild Travado
O processo parou e não avança — sinal de bad blocks ou paridade corrompida.
Bipes ou Avisos Sonoros
Sons repetitivos do storage indicam falha mecânica iminente nas cabeças de leitura.

O que é Recuperação de RAID?
A recuperação de RAID exige domínio de uma arquitetura que distribui dados entre múltiplos discos com lógica proprietária de paridade, stripe size e disk order — parâmetros que variam entre controladoras Dell PERC, HPE Smart Array, LSI MegaRAID e sistemas NAS. Quando dois ou mais discos falham, a controladora perde os metadados ou o rebuild é iniciado incorretamente, os dados tornam-se matematicamente inacessíveis sem engenharia reversa especializada — e no RAID, não existe desfazer.
Se o seu array está degradado, offline ou com Foreign Configuration, não inicie o rebuild e não force discos online. Essas ações sobrescrevem os metadados que ainda permitiriam reconstruir o volume corretamente — transformando uma falha recuperável em perda permanente. Cada reinicialização adicional sem diagnóstico forense reduz as chances de recuperação.
A E-Recovery é especialista em recuperação de RAID de todos os níveis — 0, 1, 5, 6, 10, 50 e 60 — utilizando PC-3000 e DeepSpar para clonagem forense individual de cada disco e reconstrução virtual do array em laboratório, sem nenhuma escrita nos originais. Atendemos servidores em torre, rack e datacenters de alta densidade com diagnóstico gratuito em até 48 horas e atendimento emergencial 24×7.
8250
+Projetos Executados
20
AnosExperiência
95
%Taxa de Sucesso
24
x 7Atendimento
Fale com um especialista em Recuperação de RAID agora!
O tempo é crucial. Quanto mais rápido você agir, maiores as chances na recuperação de dados de RAID. Preencha o formulário abaixo para um diagnóstico e orçamento gratuitos ou chame-nos no WhatsApp.
O que os Clientes Falam da E-Recovery
Grandes empresas confiam na E-Recovery para recuperar raid, você também pode confiar!


NAS Seagate em RAID 0 com 12 TB inacessíveis — recuperação total em dias
"Falha severa comprometeu 12 TB de dados em um NAS Seagate RAID 0. Após tentativas internas sem sucesso, a E-Recovery reconstruiu o array por engenharia reversa dos parâmetros de stripe e disk order. Volume restaurado integralmente." Autor: Tassio Lima — Analista de Infra, Portal Minha Vida
Storage CalDigit 16 TB recuperado após falha simultânea de discos por firmware
"Dois discos falharam simultaneamente após atualização de firmware, tornando o ambiente inacessível. A E-Recovery clonou cada unidade com PC-3000 e reconstruiu o RAID sem nenhuma escrita nos discos originais." Autor: Mauricio Junior — Gerente de TI, Fundação TVT
RAID 5 em servidor HPE — recuperação após perda total do array por queda de energia
"Quedas de energia progressivas derrubaram o último disco funcional do RAID 5. A E-Recovery aplicou clonagem forense e reconstrução matemática da paridade, restaurando todos os dados com integridade total." Autor: Marcos Augusto C. Peres — Consultor de TI, Projeto Guri
Storage NAS EMC Lenovo reintegrado com 100% dos dados após falha de pareamento
"Storage utilizado com gravador Avaya tornou-se inacessível após falhas repetidas. Diagnóstico identificou corrupção de metadados. Ambiente restabelecido com todas as gravações recuperadas integralmente." Autor: Departamento de TI, Olitel Brasil SA
Servidor IBM X3400 em RAID 10 recuperado após queima total da controladora
A placa controladora queimou, bloqueando o acesso ao array RAID 10 crítico. A E-Recovery extraiu os parâmetros diretamente dos discos, reconstruiu o layout virtualmente e restabeleceu o ambiente sem o hardware original." Autor: Gerência de TI, HEMAT
Gráfica Formflex, Carapicuíba/SP
Recuperação de RAID 0 + RAID 1 com dano físico
O Problema
A Formflex, gráfica de segurança de Carapicuíba/SP, chegou ao laboratório com um cenário fora do comum: um NAS Seagate de 4 discos completamente inacessível, sem controladora ativa e com dois volumes distintos corrompidos ao mesmo tempo — um em RAID 0 e outro em RAID 1. Para agravar, um dos discos apresentava danos físicos internos severos. A empresa estava paralisada. Nenhuma informação sobre a configuração original dos arrays estava disponível — e cada hora parada representava prejuízo direto para o negócio.”
Como Resolvemos
O processo começou pelo isolamento imediato do dispositivo para preservar o estado exato das mídias. Os três discos funcionais foram clonados bit-a-bit com o PC-3000 — hardware forense de nível internacional que lê setores instáveis sem forçar o desgaste das cabeças. O quarto disco, com avarias internas, passou por tratamento físico em laboratório para extração da imagem bruta antes de qualquer análise lógica.
Com todas as imagens geradas e o processo rodando exclusivamente em modo somente leitura, iniciamos a engenharia reversa do algoritmo proprietário da controladora Seagate diretamente no código hexadecimal via WinHex. Sem documentação e sem a controladora original, mapeamos manualmente a ordem das unidades, o strip size e o alinhamento de setores de cada um dos dois arrays.
O Resultado
Com os parâmetros decodificados, os ambientes de RAID 0 e RAID 1 foram remontados virtualmente em laboratório. O sistema de arquivos montou sem erros, permitindo a extração integral de aproximadamente 1 TB de dados confidenciais. Os arquivos foram entregues em novas mídias fornecidas pelo cliente, com a operação da gráfica retomada sem nenhuma perda de dados.
O Cliente: “A E-Recovery entrou muito bem no processo, recuperou todos os nossos dados, atendeu a gente fora do horário e fez um excelente preço. Precisando, por favor, contatem eles — vale muito a pena.” — Christian Uhlmann, Arquiteto
Arquiteto Christian Uhlmann
NAS Lenovo 2 discos — falha mecânica total + bad blocks simultâneos
O Problema
O escritório de Christian Uhlmann operava um mini CPD próprio com um NAS Lenovo de 2 discos para centralizar projetos de arquitetura de grande porte — arquivos que inviabilizavam o uso de nuvem convencional. Em uma mesma semana, ambos os discos colapsaram: o primeiro com falha mecânica total na mídia física, o segundo HD com bad blocks severos em setores críticos. Por pertencerem ao mesmo lote de fabricação, sofreram a mesma falha de hardware de forma simultânea. Projetos, plantas e contratos estavam em risco iminente de perda definitiva — e cada hora parada comprometia a operação do escritório.
Como Resolvemos
O caso exigiu atuação em duas frentes simultâneas. A unidade com pane física passou por intervenção mecânica em laboratório para restabelecer temporariamente a leitura dos braços magnéticos. O segundo disco, com bad blocks severos, foi tratado com hardware forense para isolar as áreas instáveis e extrair a imagem bruta sem forçar o desgaste da mídia.
Com os clones gerados e o processo rodando em modo somente leitura, aplicamos engenharia reversa na estrutura hexadecimal via WinHex para reconstruir os parâmetros lógicos do arranjo original da Lenovo. As áreas corrompidas foram contornadas e o sistema de arquivos foi remontado virtualmente, preservando a integridade das pastas e a hierarquia dos projetos.
O Resultado
100% dos arquivos e projetos de arquitetura foram extraídos com sigilo total. O atendimento foi realizado fora do horário comercial para reduzir ao máximo o tempo de empresa parada.
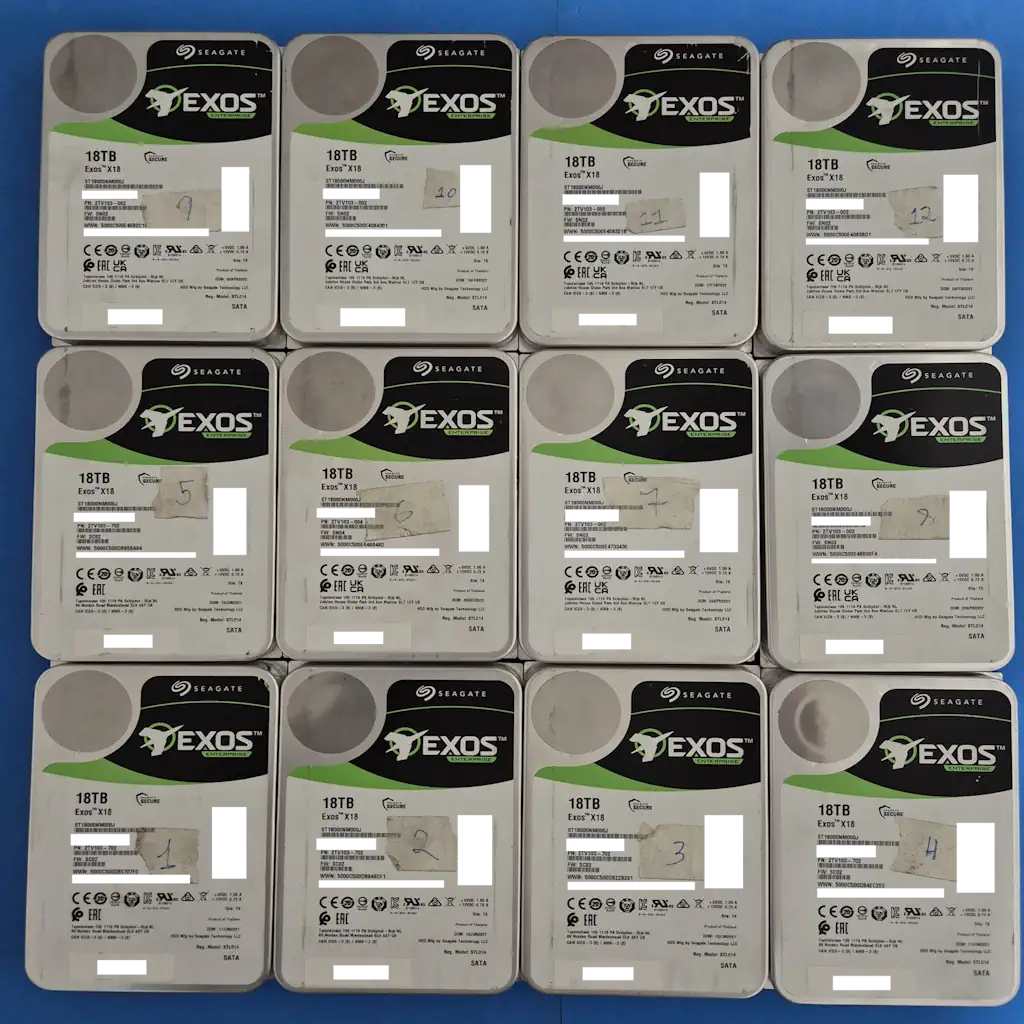
“Os 12 discos Seagate Exos X18 de 18TB numerados individualmente antes da clonagem forense — protocolo obrigatório para preservar o disk order original do array.”
SERVIDOR ASUS RS520-E9-RS12-E
Recuperação de RAID 5 com 12 discos de 18TB com rebuild
O Problema
O laboratório da E-Recovery recebeu um dos casos de maior complexidade já tratados em nossa estrutura: um servidor ASUS RS520-E9-RS12-E com 12 discos Seagate Exos Enterprise de 18TB cada — 180TB brutos configurados em array RAID para armazenamento de arquivos de vídeo de alta resolução. Antes de chegar à Vila Mariana, o equipamento havia passado por duas intervenções incorretas que transformaram um problema recuperável em um cenário que a maioria dos laboratórios classifica como perda total definitiva.
A equipe de TI interna tentou substituir o backplane do servidor sem sucesso. O array foi então encaminhado a uma empresa de assistência técnica convencional que, sem conhecimento de arquitetura forense de storages, conectou as 12 unidades diretamente a uma controladora Dell PERC incompatível com o arranjo original. A controladora injetou e gravou assinaturas físicas forçadas — metadados intrusos — no final de cada um dos 12 discos, corrompendo gravemente os metadados nativos do servidor ASUS e destruindo completamente a lógica de paridade e distribuição dos blocos do array. O volume tornou-se totalmente inacessível.
Como Resolvemos
O Processo
A recuperação exigiu 2 meses de trabalho ininterrupto estruturado em três fases críticas.
Fase 1 — Clonagem Forense: discos corporativos fatigados não toleram estresse adicional de leitura. A primeira medida foi clonar bit-a-bit cada uma das 12 unidades de 18TB para 12 novos HDs Toshiba NAS N300 de 22TB. Toda a análise subsequente foi realizada exclusivamente sobre as imagens seguras — preservando os discos originais intocados durante todo o processo.
Fase 2 — Reconstrução Lógica: via análise hexadecimal com WinHex, a equipe isolou e neutralizou as assinaturas injetadas pela controladora Dell PERC em cada disco. Com os metadados intrusos removidos, remapeamos manualmente o microcódigo do sistema de arquivos e recalculamos os parâmetros originais do array — algoritmo de rotação de paridade, stripe size e ordem exata dos discos no barramento ASUS.
Fase 3 — Entrega Dinâmica: dado o volume massivo de dados e a necessidade do cliente de manter parte da operação ativa durante o processo, os arquivos não foram retidos até o encerramento do caso. À medida que as estruturas de diretórios eram reconstruídas e validadas, os arquivos de vídeo eram extraídos dinamicamente para 12 HDs Toshiba de 20TB e entregues em lotes semanais ao cliente.
O Resultado
100% dos dados recuperados com integridade absoluta — todos os arquivos de vídeo extraídos sem corrupção de frames e com a estrutura original de pastas completamente preservada. A intervenção cirúrgica da E-Recovery reverteu um cenário declarado como perda total por outros laboratórios, salvando meses de produções audiovisuais históricas que seriam permanentemente perdidas devido às intervenções incorretas anteriores.

O Cliente: “O Orlando e sua equipe se prontificaram de imediato, dando atenção excepcional e atendendo todas as minhas expectativas.” — Fernando Andrade Ulhôa, Comitê Paralímpico Brasileiro
Comitê Paralímpico Brasileiro
Recuperação de RAID 5 com 7 discos de 2TB, queda de energia
O Problema
Uma queda de energia severa atingiu o servidor Dell corporativo do Comitê Paralímpico Brasileiro, danificando fisicamente várias unidades e destruindo a estrutura lógica do arranjo RAID 5 de 7 discos de 2TB. O volume total de 14TB continha dados institucionais altamente sensíveis. Com o acesso completamente bloqueado e a operação da entidade paralisada, a E-Recovery foi acionada em regime de urgência máxima — qualquer passo errado na remontagem do array colocaria em risco a recuperação definitiva das informações.
Como Resolvemos
Todos os 7 discos foram isolados imediatamente em nosso laboratório em São Paulo. As unidades afetadas pelo surto elétrico passaram por estabilização antes da clonagem forense bit-a-bit, garantindo que nenhuma leitura adicional agravasse o estado físico das mídias. Com os clones gerados e o processo operando exclusivamente em modo somente leitura, nossa equipe iniciou a engenharia reversa diretamente no código hexadecimal via WinHex.
Decodificamos os parâmetros proprietários da controladora Dell — ordem exata das unidades, tamanho do stripe e algoritmo de rotação de paridade — que haviam sido perdidos no colapso elétrico. O array foi remontado virtualmente em laboratório, contornando os setores danificados e reconstituindo o sistema de arquivos sem nenhum risco de sobrescrita.
O Resultado
100% dos dados recuperados com integridade absoluta. O atendimento foi conduzido em regime de plantão, com disponibilidade fora do horário comercial para minimizar o tempo de paralisação da entidade.

O Cliente: “Fiquei surpreso com a qualidade dos serviços. Parabéns pela agilidade, competência e comprometimento com os interesses dos clientes.” — Departamento de TI, Brand Têxtil
Brand Têxtil, Americana/SP
Recuperação de RAID 0 de servidor Dell com 80TB
O Problema
A Brand Têxtil, indústria de grande porte de Americana/SP, perdeu o acesso a 80TB de dados críticos quando o arranjo RAID 0 do seu servidor Dell PowerEdge T430 — composto por 8 discos de 10TB — desapareceu completamente da controladora. A causa: falhas progressivas no hardware do backplane combinadas com a degradação simultânea de duas unidades. Em arquiteturas RAID 0, um único setor ilegível compromete faixas de dados distribuídas por todos os discos. Arquivos de produção, históricos operacionais e documentos gerenciais ficaram totalmente inacessíveis, com a fábrica paralisada.
Como Resolvemos
O protocolo exigiu precisão absoluta desde o primeiro movimento. Cada um dos 8 discos de 10TB foi clonado individualmente com hardware forense especializado, isolando e lendo com segurança as áreas instáveis sem pressionar mecanicamente as cabeças de leitura já comprometidas. Com as imagens brutas protegidas e o trabalho em modo somente leitura, nossa equipe aplicou engenharia reversa no código hexadecimal via WinHex.
Reconstituímos matematicamente a ordem exata dos 8 membros do array, o tamanho das stripes e os offsets específicos da controladora Dell T430. Com o layout reconstruído virtualmente em ambiente controlado, emulamos o RAID e reestruturamos os blocos fragmentados de forma sequencial.
O Resultado
Dados extraídos com organização e integridade total. O histórico de produção e os arquivos gerenciais da indústria foram recuperados sem necessidade de reinstalar o ambiente original. Entrega com máximo sigilo.

O Cliente: “A E-Recovery cumpriu com o prazo estipulado na recuperação dos dados dos HDs, o que otimizou o processo para prosseguirmos com os trabalhos constantes nos referidos discos.” — Seicho-no-Iê Brasil, São Paulo
Seicho-no-Iê Brasil
Recuperação de RAID 0 de servidor IBM, caso recusado pela concorrência
O Problema
A Seicho-no-Iê perdeu o acesso completo à partição de dados do servidor IBM principal, estruturado em RAID 0 de alta complexidade. Antes de buscar suporte especializado, a equipe de TI tentou copiar emergencialmente os arquivos para uma mídia externa enquanto as pastas ainda estavam parcialmente visíveis — o processo travou e o volume colapsou por completo. A situação se agravou quando outra empresa de recuperação avaliou o caso e declarou não ter capacidade técnica para executar o serviço. Foi então que o caso foi encaminhado à E-Recovery.
Como Resolvemos
Como Resolvemos
A recusa da concorrência sinalizava que o arranjo IBM possuía blocos altamente fragmentados e metadados comprometidos pelas tentativas de cópia forçada. Isolamos as mídias originais e realizamos a clonagem física bit-a-bit setor a setor em modo somente leitura em nossas estações forenses, preservando o estado exato dos dados sem nenhum estresse adicional.
Com a imagem bruta protegida, aplicamos engenharia reversa na estrutura hexadecimal via WinHex. Decodificamos manualmente o algoritmo proprietário de distribuição de dados da controladora IBM, realinhamos os setores lógicos travados pela tentativa de cópia e reconstruímos virtualmente o array do zero — remontando a partição sem tocar nos discos originais.
O Resultado
O que o mercado considerou irrecuperável foi solucionado dentro do prazo acordado. Dados vitais extraídos com integridade total, permitindo à instituição retomar imediatamente os trabalhos que dependiam daqueles arquivos.

20 Anos Recuperando o que Outros Não Conseguem
Quem Somos
Com uma avaliação ⭐⭐⭐⭐⭐ de 4.9 / 5.0 em mais de 120 depoimentos no Google, e muitas outras história de sucesso compartilhadas diretamente em nosso site, a satisfação dos nossos clientes fala por si.
A E-Recovery é especialista em recupera dados de RAID de alta complexidade para servidores, storages NAS e ambientes virtualizados. Fundada em 2001, acumulamos mais de 20 anos de atuação e mais de 8.200 casos concluídos — tornando-nos referência nacional em cenários onde outras empresas não conseguem avançar.
Nossa equipe técnica de recuperação de RAID trabalha exclusivamente sobre clones forenses dos dispositivos originais, utilizando hardware profissional como PC-3000 e DeepSpar em laboratório próprio em São Paulo. Cada caso recebe análise individualizada — sem soluções genéricas, sem atalhos.
- Hardware forense de nível profissional: PC-3000, DeepSpar
- Confidencialidade total e NDA sob solicitação
- Atendimento emergencial 24×7 via WhatsApp e telefone
- Laboratório próprio em São Paulo/SP na Vila Mariana.
- E mais 4 unidades de recebimento na Barra Funda, Morumbi, Pinheiros e Tatuapé.
Laboratório Central Vila Mariana
Edifício Berkeley Office Center – Av Professor Noé de Avevedo 208 cj 65 – Vila Mariana – São Paulo/SP – CEP 04117-000
Unidade de Recebimento Barra Funda
Edifício Casa das Caldeiras – Av. Francisco Matarazzo, 1752 – sala 1511 – Barra Funda, São Paulo – SP, CEP 05001-200.
Unidade de Recebimento Morumbi
Edifício Giovanni Gronchi Offices Center – Av. Giovanni Gronchi, 6195 sala 310 – Vila Andrade, S. Paulo – SP, 05724-003.
Unidade de Recebimento Pinheiros
Edifício Ahead – R. Cláudio Soares, 72 – cj 1113 e 1114 no 11º andar – Pinheiros, S. Paulo – SP, CEP 05422-030
Unidade de Recebimento Tatuapé
Edifício Paul Harris – R. Padre Adelino, 2074 – conjuntos 121/122 – Tatuapé, São Paulo – CEP 03303-000
Não arrisque seus dados. Fale com um especialista em RAID agora!
O tempo é crucial. Quanto mais rápido você agir, maiores as chances de recuperação. Preencha o formulário abaixo para um diagnóstico e orçamento gratuitos ou chame-nos no WhatsApp.

Perguntas Frequentes sobre Recuperação de RAID
Qual o prazo para o diagnóstico emergencial de um servidor ou storage RAID?
RESPOSTA: Para casos corporativos em urgência, iniciamos a análise imediatamente após a entrada do equipamento em nosso laboratório em São Paulo. O diagnóstico técnico completo — identificando viabilidade, nível de dano físico ou lógico e chances reais do serviço de recuperação de RAID — é emitido em poucas horas para que sua empresa tome a decisão o mais rápido possível.
A E-Recovery assina Acordo de Confidencialidade (NDA) com empresas?
RESPOSTA: Sim, em todos os atendimentos. Tratamos dados corporativos sob o mais estrito sigilo e fornecemos um Acordo de Confidencialidade (NDA) padrão para recuperar RAID, que pode ser assinado digitalmente antes mesmo do envio dos discos. Se sua empresa possuir modelo próprio de compliance ou termo de sigilo, nossa equipe avalia e assina de imediato.
É possível recuperar RAID remotamente, sem enviar os discos?
RESPOSTA: Em arranjos com qualquer tipo de falha física — discos com bad blocks, estalo mecânico, queima de cabeças de leitura ou dano por oscilação elétrica — o acesso remoto para recuperar RAID é totalmente inviável e perigoso. A recuperação segura exige manipulação física das mídias em laboratório com hardware forense em modo somente leitura. O acesso remoto para recuperar dados RAID só é avaliado em cenários puramente lógicos e específicos, após triagem técnica rigorosa.
Como funciona o envio dos discos ou do storage para o laboratório?
RESPOSTA: Você envia apenas os discos do array — não é necessário enviar o servidor, storage, gavetas ou controladora para recuperar RAID. Antes de remover os discos, numere a ordem exata de cada unidade nas baias (Disco 0, Disco 1, Disco 2…). Embale individualmente em plástico bolha, dentro de uma caixa rígida com proteção. Atendemos recuperação de RAID presencialmente em São Paulo ou por envio via Correios/transportadora de todo o Brasil.
O que acontece se os dados do meu RAID não puderem ser recuperados?
Nossa política é No Data, No Fee: se não for possível recuperar os dados, você não paga pelo serviço. Existem exceções previamente informadas para casos que envolvem danos físicos severos, ou casos muitos complexos na recuperação de RAID. Em todos os casos, você recebe um laudo técnico detalhado explicando as causas da inviabilidade antes de qualquer decisão.
Recuperar RAID 5 com dois discos falhando é possível?
RESPOSTA: Sim, em muitos casos é possível recuperar dados de RAID, mesmo com falha dupla no RAID 5 — que ultrapassa o limite de tolerância da arquitetura — nossa engenharia atua por reconstrução matemática inversa, analisando os stripes válidos remanescentes e corrigindo inconsistências de paridade diretamente no código hexadecimal. O sucesso depende do estado físico dos discos sobreviventes e de não ter havido tentativas de rebuild ou sobrescrita após a falha.
O NAS mostra "crashed volume" ou "volume degraded". Tem solução?
RESPOSTA: Sim. Em storages Synology, QNAP e Asustor, volumes entram em estado crashed ou degraded por corrupção de metadados MDADM, falha no sistema de arquivos EXT4, Btrfs ou ZFS, ou degradação física de discos. A recuperação de RAID envolve clonagem forense de cada unidade, reconstrução das estruturas lógicas corrompidas e remontagem virtual do volume — sem depender do hardware original do NAS.
A controladora RAID queimou. Perdi os dados definitivamente?
RESPOSTA: Não. A configuração do array pode ser extraída diretamente dos discos, sem depender da controladora original. Após a clonagem forense de cada unidade, identificamos os parâmetros do RAID — ordem dos discos, stripe size, offset e algoritmo de paridade — diretamente no código hexadecimal das mídias via WinHex. Com a Recuperação de RAID, o volume é reconstruído virtualmente em laboratório sem nenhuma dependência do hardware queimado.
O rebuild travou no meio do processo. O que devo fazer?
RESPOSTA: Interrompa imediatamente. Rebuild travado é sinal de bad blocks ou paridade inconsistente em outros discos do array. Forçar a continuação pode destruir blocos válidos e tornar a recuperação inviável. A ação correta é desligar o servidor de forma controlada, preservar a ordem dos discos nas baias e encaminhar o conjunto para análise forense em laboratório especializado em recuperar RAID antes de qualquer nova tentativa.
Posso usar software de recuperação de RAID como R-Studio ou TestDisk no meu RAID?
RESPOSTA: Apenas se todos os discos estiverem íntegros e a falha for estritamente lógica. Em casos com lentidão, ruídos mecânicos, paridade quebrada, rebuild interrompido ou controladora com falha, softwares automáticos são altamente perigosos — eles forçam leituras repetidas em discos instáveis e podem sobrescrever blocos válidos, causando perda definitiva. A abordagem segura é a clonagem forense em modo somente leitura antes de qualquer análise para recuperar RAID de modo totalmente seguro.
É seguro reiniciar o servidor após uma falha de RAID?
RESPOSTA: Não é recomendado. Cada reinicialização força o sistema a tentar remontar o array, o que pode acionar rebuilds automáticos sobre discos já instáveis ou agravar danos mecânicos em unidades com falha física incipiente. O procedimento correto após qualquer alerta crítico de RAID é desligar o servidor de forma controlada, documentar os alertas da controladora e buscar diagnóstico especializado antes de qualquer nova inicialização.
Vocês recuperam Máquinas Virtuais (VMware ESXi, Hyper-V) armazenadas no RAID?
RESPOSTA: Sim, é uma das nossas principais especialidades. Não recuperamos apenas arquivos — recuperamos ambientes completos. O processo inclui a reconstrução do array físico, a análise do sistema de arquivos do hipervisor (VMFS no VMware, NTFS/ReFS no Hyper-V) e a extração dos discos virtuais (.VMDK, .VHDX) íntegros e prontos para importação em um novo servidor. Bancos de dados SQL, Oracle e sistemas ERP virtualizados são recuperados com integridade transacional.

Mais de 250 Histórias de Sucesso — Avaliação 4.9 no Google
Com uma avaliação ⭐⭐⭐⭐⭐ de 4.9 / 5.0 em mais de 120 depoimentos no Google, e muitas outras história de sucesso em recuperar RAID compartilhadas diretamente em nosso site, a satisfação dos nossos clientes fala por si.
Descubra por que tantos confiam em nós para a recuperação de seus dados mais valiosos. Clique no botão abaixo e veja porque a E-Recovery é empresa com melhor reputação do mercado.
Por que Empresas e Departamentos de TI Confiam na E-Recovery
ACOMPANHAMENTO
Cada caso de recuperação de dados de RAID recebe um especialista dedicado como ponto único de contato. Você é atualizado de forma proativa sobre cada etapa técnica e operacional, sem precisar solicitar informações ou cobrar retorno.
ESPECIALIZAÇÃO
Somos 100% dedicados à recuperar dados de RAID. Não vendemos peças e não fazemos manutenção geral. Esse foco exclusivo garante domínio técnico profundo, equipamentos avançados e procedimentos que apenas um laboratório especializado pode oferecer.
ATENDIMENTO 24X7
Ambientes corporativos não podem parar. Casos de RAID entram automaticamente em fluxo emergencial 24×7, da triagem à entrega dos dados. O processo é otimizado, reduzindo ao máximo o tempo de indisponibilidade do seu ambiente.
SEM DADOS, SEM CUSTOS
Você só realiza o pagamento após validar os dados essenciais para sua operação. Se não houver recuperação viável, você não paga pelo serviço (exceto em casos informados previamente). Risco zero para sua empresa.
CONFIDENCIALIDADE
Tratamos seus dados em redes isoladas e seguras, com NDA assinado em todos os atendimentos. Todo o processo é executado por engenheiros especializados, garantindo sigilo absoluto e proteção completa das informações.
TRANSPARÊNCIA
Entregamos diagnóstico técnico completo e orçamento detalhado, com causas da falha, chances de sucesso e prazos. Sem letras miúdas, sem custos ocultos e sem surpresas — comum ou emergencial.

Como Funciona o Processo?
Veja como funciona o processo de recuperação de dados de RAID, do começo ao fim, com total clareza e sem surpresas.
Contato Inicial e Entrega do Servidor / Discos do RAID
Você poderá enviar apenas os discos do array, devidamente numerados ou identificados. Não é necessário enviar servidor, storage, gavetas, backplane ou controladora RAID. Tudo será reconstruído virtualmente no nosso laboratório próprio em São Paulo através de estações forenses avançadas PC-3000 e sistemas de imagem DeepSpar. Um especialista assume o caso desde o início e orienta como embalar e enviar os discos com segurança, evitando qualquer risco adicional de danos. O atendimento é presencial na nossa Matriz Vila Mariana (SP) e logística nacional via Sedex.
Diagnóstico e Orçamento
Realizamos diagnóstico técnico detalhado em até 48h (ou emergencial 24/7), identificando ordem dos discos, níveis do RAID, saúde de cada unidade, falhas de paridade, inconsistências de metadados e riscos envolvidos. Com isso, emitimos um orçamento transparente para a recuperação de dados de RAID, com chances reais de sucesso.
Recuperação em Laboratório
Clonamos cada disco usando PC3000/DeepSpar com leitura controlada, estabilizando unidades degradadas e preservando a integridade dos dados. Em seguida, reconstruímos matematicamente o RAID (paridade, offsets, stripes, disco stale, grupos 5/6/50/60, JBOD/SPAN), até recuperar o layout original do volume.
Validação dos Dados Recuperados
Antes de qualquer pagamento, você visualiza a lista completa de arquivos recuperáveis, pastas críticas e bancos de dados. Somente após confirmar que o resultado atende às necessidades operacionais, o processo segue para finalização.
Pagamento do Serviço
Com a validação concluída, é feito o pagamento conforme acordado. Não há cobrança caso a recuperação não seja viável (exceto em casos previamente informados de serviços especiais).
Entrega e Retirada dos Dados
Os dados são entregues em novos HDs externos fornecido pela empresa. Também podemos disponibilizar acesso seguro para transferência remota, conforme necessidade (com custos adicionais).
Encerramento e Apagamento Seguro dos Dados
Após a entrega, realizamos o apagamento seguro das imagens e clones utilizados no processo após 7 dias corridos, seguindo padrões profissionais de segurança e confidencialidade. Nenhuma cópia é mantida sem autorização formal.
Não arrisque seus dados. Fale com um especialista em RAID agora!
O tempo é crucial. Quanto mais rápido você agir, maiores as chances na recuperação de dados de RAID. Preencha o formulário abaixo para um diagnóstico e orçamento gratuitos ou chame-nos no WhatsApp.
Endereço:
Av Professor Noé de Avevedo 208 cj 65 - Vila Mariana - São Paulo/SP - CEP 04117-000
Telefone / WhatsApp
Voz: (11) 3422-0066
WhatsApp: (11) 93075-5919
contato@e-recovery.com.br
FORMULÁRIO DE SOLICITAÇÃO DE ORÇAMENTO PARA RAID
Guia Técnico
O que é RAID e Como Funciona a Redundância em Servidores
Todo servidor corporativo que armazena dados críticos enfrenta, em algum momento, a mesma pergunta fundamental: o que acontece com as informações da empresa quando um disco para de funcionar? O RAID — Redundant Array of Independent Disks — surgiu exatamente para responder a essa pergunta com uma solução de engenharia que combina múltiplos discos físicos em um único volume lógico, distribuindo os dados de forma inteligente entre as mídias para garantir que a falha de uma unidade isolada não paralise a operação.
Na prática, quando um administrador de TI configura um RAID em um servidor Dell PowerEdge, um storage Synology ou um NAS QNAP, ele está instruindo a controladora a gerenciar automaticamente como cada byte gravado pelo sistema operacional será distribuído entre os discos físicos do conjunto. O sistema operacional enxerga um único disco lógico de grande capacidade — mas por baixo, a controladora está coordenando leituras e escritas em paralelo entre duas, quatro, seis ou até dezenas de mídias físicas simultaneamente.
Essa arquitetura oferece dois benefícios concretos para o negócio: velocidade — porque múltiplos discos lendo em paralelo multiplicam a taxa de transferência de dados — e segurança operacional — porque determinados níveis de RAID conseguem continuar funcionando mesmo com um ou dois discos fisicamente mortos. É por isso que servidores de bancos de dados, ambientes de virtualização VMware e storages de missão crítica dependem do RAID como base da infraestrutura de armazenamento.
Como a Controladora Distribui os Dados
A inteligência do RAID está na controladora — o componente de hardware ou software responsável por decidir, a cada operação de escrita, como fragmentar e distribuir os dados entre os discos do conjunto. Essa distribuição segue três técnicas fundamentais que determinam o comportamento do array e, criticamente, o que acontece quando ele falha.
A primeira técnica é o striping — a fragmentação dos dados em blocos de tamanho fixo chamados stripe size ou chunk, que variam tipicamente entre 64KB e 512KB. Cada bloco é gravado em um disco diferente do conjunto em sequência cíclica. Um arquivo de 512KB em um array de quatro discos com stripe size de 128KB terá seus quatro blocos gravados um em cada disco simultaneamente — multiplicando a velocidade de escrita por quatro. A consequência direta é que, se a ordem exata desses blocos for perdida por falha de controladora ou troca acidental de disco, os dados se tornam uma sequência ininteligível de bytes sem o mapa de reconstrução original.
A segunda técnica é o mirroring — a replicação bit-a-bit de tudo que é gravado em um disco para um segundo disco em tempo real. É o mecanismo mais simples e mais robusto de proteção — qualquer falha em um dos discos é absorvida transparentemente pelo espelho. O custo é o aproveitamento de apenas 50% da capacidade total instalada, tornando-o mais caro por gigabyte útil.
A terceira técnica é o cálculo de paridade — a mais sofisticada das três. Em vez de duplicar os dados fisicamente, a controladora realiza uma operação matemática chamada XOR (Exclusive OR) sobre os blocos gravados nos discos, gerando um bloco de controle que permite reconstruir qualquer disco perdido a partir dos demais. O RAID 5 usa uma paridade simples; o RAID 6 usa paridade dupla com algoritmos Reed-Solomon para tolerar a perda de dois discos simultaneamente. A elegância matemática desse mecanismo esconde, no entanto, uma fragilidade crítica: qualquer inconsistência no cálculo de paridade — causada por queda de energia durante uma escrita, bad blocks nos discos sobreviventes ou bugs de firmware — pode tornar a reconstrução matematicamente impossível sem intervenção forense especializada.
Por que o RAID Não É Backup
A confusão mais perigosa no ambiente corporativo é tratar o RAID como substituto de backup. Essa percepção equivocada é responsável por uma parcela significativa dos casos críticos que chegam ao laboratório — empresas que operaram por anos acreditando que a redundância do array as protegia de qualquer perda de dados, até o dia em que dois discos falharam simultaneamente, um ransomware criptografou o volume inteiro ou um bug de firmware corrompeu os metadados da controladora.
O RAID protege exclusivamente contra a interrupção causada pela falha física de uma ou duas mídias dentro do limite de tolerância da arquitetura. Ele não oferece nenhuma proteção contra exclusão acidental de arquivos, corrupção lógica do sistema de arquivos, ataques de ransomware que criptografam os dados em nível de bloco, erros humanos durante manutenções ou falhas simultâneas que ultrapassem o limite de tolerância do nível configurado. Quando o array colapsa por qualquer uma dessas razões, a única solução é a engenharia reversa forense em laboratório especializado — um processo que começa onde as ferramentas convencionais de TI terminam.
Guia Técnico
Guia Completo dos Níveis de RAID: Do RAID 0 ao RAID 60 e JBOD
RAID 0 – Strippping e Redundância Zero
O RAID 0 distribui os dados em blocos alternados entre todos os discos do conjunto sem qualquer redundância. Com dois discos de 4TB, você obtém um volume de 8TB com velocidade de leitura e escrita dobrada — mas qualquer falha física em qualquer um dos discos destrói todo o array instantaneamente. Não existe tolerância a falhas de nenhum nível.
É amplamente usado em estações de edição de vídeo, servidores de renderização e ambientes de alta performance onde a velocidade supera a necessidade de redundância. O problema é que muitas empresas constroem servidores de produção em RAID 0 por desconhecimento ou por buscar o máximo de capacidade com o menor custo — e pagam o preço quando o primeiro disco falha.
A recuperação de RAID 0 exige que todos os discos estejam presentes e que a geometria original — stripe size, ordem dos discos e offsets — seja reconstruída por engenharia reversa. Casos como o da Brand Têxtil, que perdeu 80TB em um Dell PowerEdge T430 com 8 discos em RAID 0, ilustram a complexidade: cada disco contém apenas fragmentos do arquivo original, e reconstituir a sequência exata dos blocos sem o mapa da controladora original é um processo que exige análise hexadecimal manual disco a disco.
RAID 1 — Espelhamento e a Armadilha do Disco Obsoleto
O RAID 1 mantém cópias idênticas dos dados em dois ou mais discos simultaneamente. É a escolha padrão para discos de sistema operacional em servidores, volumes de boot em ambientes VMware e storages de pequeno porte onde a disponibilidade é prioritária. A capacidade útil é de 50% do total instalado.
O cenário de falha mais comum em RAID 1 não é a perda simultânea dos dois discos — é o disco obsoleto (stale drive). Quando o espelhamento perde sincronismo por uma queda de energia ou erro lógico e o servidor continua operando por dias ou semanas com apenas um disco ativo, o segundo disco vai gradualmente ficando desatualizado. Quando ele falha definitivamente, o administrador tenta forçar o disco obsoleto de volta online — e descobre que os dados que estavam nele são de semanas atrás, gerando inconsistências graves nos bancos de dados e arquivos de produção.
RAID 5 — O Padrão Corporativo e Sua Principal Fraqueza
O RAID 5 é o nível mais utilizado em ambientes corporativos de pequeno e médio porte — storages NAS, servidores de arquivos e ambientes de virtualização de entrada. Distribui os dados e a paridade entre todos os discos, tolerando a falha de exatamente um disco sem perda de dados. Com quatro discos de 4TB, você obtém 12TB úteis com proteção de um disco.
A fraqueza crítica do RAID 5 está no rebuild após uma falha: o processo de reconstrução lê 100% dos dados de todos os discos sobreviventes para recalcular os blocos do disco perdido. Em discos de grande capacidade, isso pode levar 24 a 72 horas — e durante todo esse período, se qualquer setor defeituoso for encontrado nos discos sobreviventes, o rebuild trava ou falha, colapsando o array inteiro. Esse é o cenário mais frequente no laboratório: RAID 5 que entrou em modo degradado, o administrador iniciou o rebuild sem diagnóstico forense prévio, e um segundo disco com bad blocks silenciosos derrubou o volume definitivamente.
RAID 6 — Dupla Paridade para Ambientes de Missão Crítica
O RAID 6 adiciona um segundo bloco de paridade independente calculado com o algoritmo Reed-Solomon, tolerando a falha simultânea de dois discos. É a escolha padrão para storages de grande capacidade, ambientes de virtualização críticos e NAS corporativos com discos de alta capacidade onde o risco de falha dupla durante um rebuild é estatisticamente relevante.
A recuperação de RAID 6 com dois ou mais discos offline exige processamento das equações Reed-Solomon sobre as imagens forenses de todos os discos sobreviventes — um processo computacionalmente intensivo que pode levar horas ou dias dependendo da capacidade do array e do nível de dano nas mídias.
RAID 10 — Performance e Segurança sem Compromisso
O RAID 10 combina espelhamento e striping: cria pares de discos espelhados e distribui os dados entre esses pares em stripe. Com seis discos de 4TB, você obtém 12TB úteis com velocidade próxima ao RAID 0 e tolerância a múltiplas falhas — desde que os discos que falharem não pertençam ao mesmo par espelhado.
É a arquitetura padrão para servidores de banco de dados SQL Server, Oracle e MySQL, e para hosts VMware ESXi de alto desempenho. O caso do IBM X3400 da HEMAT com RAID 10 e controladora queimada é um exemplo real da recuperação dessas arquiteturas: sem a controladora original, os parâmetros do array precisam ser deduzidos diretamente dos metadados ocultos nos primeiros setores de cada disco.
RAID 50 e RAID 60 — Arquiteturas Corporativas de Alta Densidade
O RAID 50 combina múltiplos grupos de RAID 5 unidos por um RAID 0 superior, oferecendo tolerância a múltiplas falhas em diferentes grupos com alta capacidade líquida. O RAID 60 faz o mesmo com grupos de RAID 6, adicionando dupla paridade em cada subgrupo. São utilizados em data centers, storages SAN de grande porte e ambientes de virtualização de alta densidade.
A recuperação dessas arquiteturas exige engenharia reversa em duas camadas: primeiro a reconstrução da geometria do RAID 0 superior, depois a reconstrução individual de cada subgrupo de RAID 5 ou RAID 6 — um processo que pela complexidade geométrica está fora do alcance de qualquer software automático de recuperação disponível no mercado.
JBOD — Concatenação sem Redundância
O JBOD — Just a Bunch of Disks — simplesmente emenda discos em sequência, preenchendo um antes de avançar para o próximo. Não há redundância, não há striping — e quando um disco do meio da cadeia falha, todos os arquivos que cruzavam aquela fronteira física ficam corrompidos. A recuperação exige mapeamento das fronteiras físicas entre os discos para extrair os arquivos íntegros de cada segmento individualmente.
Guia Técnico
Por que os Arranjos RAID Falham: As 5 Principais Causas de Colapso
Depois de décadas atendendo casos de colapso de servidores corporativos, o laboratório da E-Recovery identificou padrões recorrentes que precedem a maioria das perdas de dados em arrays RAID. Raramente uma falha catastrófica ocorre de forma repentina e sem aviso — quase sempre existe uma sequência de eventos que, se identificada precocemente, poderia ter evitado a paralisação total da operação.
1. Falha em Cascata por Discos do Mesmo Lote
O storage Caldigit da Fundação TVT funcionou por anos sem problemas até que uma atualização de firmware precipitou a falha simultânea de dois discos. O da Brand Têxtil operou normalmente até que a degradação progressiva do backplane derrubou duas unidades do RAID 0 ao mesmo tempo. O padrão se repete: discos comprados juntos, do mesmo fabricante e lote, envelhecem juntos.
Quando todos os discos de um array são instalados simultaneamente e submetidos às mesmas condições de operação — mesma temperatura, mesma carga de trabalho, mesma vibração — eles acumulam desgaste no mesmo ritmo. O primeiro disco a falhar entra em modo degradado e a controladora começa a recalcular paridade com esforço adicional dos discos sobreviventes. Esse estresse extra acelera o desgaste de um segundo disco que já estava no limite — e quando ele falha, o array colapsa inteiramente. O intervalo entre a primeira e a segunda falha pode ser de horas ou dias.
A prevenção é simples: monitoramento S.M.A.R.T. automatizado e substituição preventiva ao primeiro sinal de degradação, sem esperar a falha completa.
2. Queima de Controladora e Surtos no Backplane
A controladora RAID é o componente que mantém o mapa completo do array — a ordem dos discos, o stripe size, os offsets e o algoritmo de paridade. Esse mapa fica armazenado na memória não-volátil NVRAM da controladora ou gravado nos primeiros setores de cada disco em formato DDF.
Um surto de tensão elétrica pode queimar os circuitos da controladora instantaneamente — como aconteceu com o servidor IBM X3400 da HEMAT. Sem a controladora original, o servidor simplesmente não reconhece mais os discos como um array. O que muitos técnicos fazem nesse momento é o erro fatal: tentar importar a configuração em uma controladora nova ou de outro servidor, o que pode sobrescrever os metadados DDF e destruir permanentemente o mapa que permitiria a recuperação.
A ação correta é desligar o servidor imediatamente, preservar todos os discos na ordem original das baias e encaminhar para laboratório especializado — onde a geometria do array pode ser reconstruída diretamente dos metadados gravados nas mídias, sem depender do hardware queimado.
3. Bit Rot — Corrupção Silenciosa de Dados
O Bit Rot é a degradação gradual e silenciosa dos dados armazenados — blocos que perdem suas propriedades magnéticas ou elétricas ao longo do tempo sem gerar qualquer alerta no sistema. Esse fenômeno é estatisticamente inevitável em discos de grande capacidade operando por anos, e se torna crítico precisamente durante o rebuild: quando a controladora tenta ler todos os setores de todos os discos para reconstruir o disco perdido, encontra um setor ilegível nos dados de paridade ou nos dados principais e não consegue completar o cálculo matemático.
O resultado é um rebuild que trava em alguma porcentagem — 23%, 67%, 91% — e não avança mais. Cada tentativa de reiniciar o rebuild aumenta o estresse mecânico nos discos e reduz as chances de recuperação. A solução correta é interromper o processo imediatamente e realizar clonagem forense antes de qualquer nova tentativa de reconstrução.
4. Bugs de Firmware e Atualizações Mal-sucedidas
O caso da Fundação TVT é o exemplo mais ilustrativo: uma atualização de firmware aparentemente rotineira no storage CalDigit resultou na falha simultânea de dois discos e na perda de acesso a todo o acervo audiovisual da emissora. O Gerente de TI Maurício Júnior tomou a decisão correta de não executar nenhuma ferramenta genérica sobre o array vivo antes de buscar recuperação especializada — uma escolha que foi determinante para o sucesso do processo.
Atualizações de firmware em storages e controladoras RAID são operações de alto risco quando executadas em sistemas ativos e sob carga. Uma queda de energia durante o processo de flash, um bug de compatibilidade com a tabela de alocação de arquivos existente ou uma falha na validação do novo microcódigo podem corromper os metadados do sistema de arquivos — EXT4, Btrfs, ZFS ou NTFS — de forma que o volume deixa de montar imediatamente após a reinicialização. A regra é simples: nunca atualize firmware de storage sem backup validado e sem janela de manutenção planejada com rollback preparado.
5. Ransomware e Erro Humano
Os ataques de ransomware modernos são projetados especificamente para atingir servidores RAID e ambientes NAS em rede, criptografando não apenas os arquivos mas as próprias estruturas de metadados do sistema de arquivos para maximizar o dano. Storages QNAP e Synology foram alvos frequentes de campanhas específicas nos últimos anos, com variantes que conseguem comprometer múltiplos volumes antes de ser detectadas.
O erro humano em momentos de pressão é igualmente devastador — e frequentemente agrava uma situação que ainda seria recuperável. Um comando mdadm –zero-superblock executado no disco errado, um dd com origem e destino trocados, ou uma tentativa de reformatar o volume para “começar do zero” são ações irreversíveis que destroem os metadados necessários para a recuperação. O caso da Politran chegou ao laboratório exatamente nessa condição: após quatro rodadas de scandisk automático forçado pelo sistema, os metadados da partição estavam tão comprometidos que a recuperação exigiu mapeamento manual do código hexadecimal setor a setor para reconstituir a tabela de partições original.
Guia Técnico
O Perigo do Rebuild e Softwares Automáticos para Recuperar Dados de RAID
Existe um momento específico na trajetória de toda falha de RAID que determina se a história vai terminar com recuperação completa ou com perda definitiva. Esse momento não é a falha do primeiro disco — é a reação do administrador de TI nos primeiros minutos após o alerta. Duas ações parecem intuitivamente corretas nesse momento e são, na prática, as mais destrutivas que existem: iniciar o rebuild imediatamente e rodar um software de recuperação no servidor afetado.
Por que o Rebuild Automático Destrói Arrays que Seriam Recuperáveis
Quando a controladora exibe o alerta de disco com falha e sugere a inserção de um Hot Spare para iniciar o rebuild, a lógica parece simples — substituir o disco morto e deixar o sistema se reconstruir automaticamente. O problema está no que acontece com os discos sobreviventes durante esse processo.
Para reconstruir os dados do disco perdido, a controladora precisa ler cada setor de cada disco sobrevivente do array para recalcular os blocos faltantes. Em um RAID 5 com quatro discos de 8TB, isso significa ler aproximadamente 24TB de dados de forma contínua — um processo que pode levar entre 18 e 36 horas dependendo da velocidade dos discos e da carga do sistema. Durante todo esse tempo, os discos sobreviventes operam sob carga máxima, com temperatura elevada e heads se movendo incessantemente.
Aqui está o problema real: discos que já acumulam desgaste, bad blocks silenciosos ou degradação magnética — características invisíveis ao monitoramento convencional — chegam ao limite precisamente sob esse estresse prolongado. Quando a controladora encontra um setor ilegível em um disco sobrevivente durante o rebuild, ela não consegue completar o cálculo de paridade para aquele stripe. A resposta automática é tentar reler o setor dezenas ou centenas de vezes — aquecendo o disco progressivamente até que as cabeças de leitura percam o alinhamento nanométrico e colidam com a superfície magnética. Esse impacto — o Head Crash — risca fisicamente os pratos do disco e destrói permanentemente os dados naqueles setores.
O resultado é um array que entrou no rebuild com um disco morto e saiu com dois discos mortos e dados parcialmente destruídos. O caso da Fundação TVT chegou ao laboratório exatamente nessa condição — e a diferença entre o sucesso da recuperação e a perda total foi a decisão do Gerente de TI de interromper qualquer intervenção antes de buscar ajuda especializada.
O procedimento correto ao identificar um rebuild travado ou um alerta de segundo disco em falha durante a reconstrução é uma única ação: desligar o servidor de forma controlada, preservar os discos na ordem original das baias e encaminhar para análise forense antes de qualquer nova tentativa.
Por que Softwares Automáticos São Inadequados para RAID com Falhas Físicas
A segunda armadilha mais comum é a instalação de softwares comerciais de recuperação — R-Studio, TestDisk, Disk Drill, GetDataBack — diretamente no servidor afetado ou em um computador conectado ao array via USB. Esses programas são amplamente divulgados como soluções para recuperação de RAID e criam uma percepção de segurança que não corresponde à realidade técnica de arranjos com falhas físicas.
O problema fundamental é que esses softwares operam em modo ativo sobre as mídias — realizando varreduras sequenciais que forçam as cabeças dos discos instáveis a percorrerem repetidamente os mesmos setores defeituosos. Para um disco com desgaste de cabeças ou instabilidade de firmware, esse stress mecânico adicional pode precipitar exatamente o Head Crash que tornará a recuperação impossível.
Existe ainda o risco de sobrescrita direta. Quando o sistema operacional do servidor é inicializado para rodar o software de recuperação, ele começa imediatamente a gravar arquivos temporários, logs de sistema, dados de paginação de memória e atualizações de índice nas mídias. Como a geometria do RAID está corrompida, o sistema operacional pode interpretar blocos que contêm dados válidos como espaço livre disponível e sobrescrevê-los. Dados sobrescritos são irrecuperáveis por qualquer tecnologia existente.
Softwares automáticos têm aplicação legítima apenas em um cenário muito específico: todos os discos fisicamente íntegros e falha estritamente lógica sem bad blocks, ruídos mecânicos ou lentidão de leitura. Em qualquer outra situação — e a esmagadora maioria dos casos que chegam ao laboratório não se enquadra nessa exceção — a abordagem correta é a clonagem forense em modo somente leitura antes de qualquer análise.
A Única Ação Segura
Independentemente do nível de RAID, da marca do servidor ou da urgência da situação, existe apenas uma sequência de ações que preserva as chances de recuperação: parar todas as operações sobre as mídias, desligar o servidor de forma controlada, documentar os alertas da controladora com fotos ou registros escritos, numerar e preservar os discos na ordem original das baias, e encaminhar para laboratório especializado sem tentar nenhuma intervenção adicional.
Cada hora que o servidor permanece ligado após uma falha grave reduz as chances de recuperação. Cada tentativa de rebuild, cada execução de software, cada reinicialização cria novas oportunidades de sobrescrita e dano mecânico. A velocidade correta em uma emergência de RAID não é a velocidade de agir — é a velocidade de parar.
Guia Técnico
Recuperar Dados RAID em Ambientes Virtualizados
A virtualização transformou fundamentalmente a forma como as empresas utilizam servidores físicos — e transformou igualmente a complexidade dos processos de recuperação de dados quando o storage subjacente falha. Um servidor físico com RAID que perdia dados em 2010 era um problema de uma camada: reconstruir o array e extrair os arquivos. O mesmo servidor em 2026, rodando 20 máquinas virtuais com VMware ESXi sobre um RAID 5, é um problema de quatro camadas — e cada camada tem seus próprios metadados, estruturas de alocação e pontos de falha independentes.
O que Muda Quando o RAID Sustenta um Ambiente Virtualizado
Quando o storage físico de um host VMware ESXi falha, o que o administrador perde não são apenas arquivos — são servidores inteiros. Um único arquivo .VMDK pode representar o servidor de e-mail corporativo com anos de histórico, o ERP com todos os dados financeiros da empresa ou o servidor de arquivos com a produção de toda uma equipe. Recuperar esses ambientes não é apenas extrair bytes — é restabelecer sistemas operacionais funcionais com todas as configurações, bancos de dados com integridade transacional e arquivos de aplicação sem corrupção.
A complexidade da recuperação se multiplica porque a falha do RAID físico corrompeu estruturas em múltiplas camadas simultaneamente. A controladora perdeu os metadados do array — esse é o primeiro problema. O sistema de arquivos do hipervisor ficou inconsistente porque o array caiu no meio de uma operação de escrita — esse é o segundo. E os arquivos de disco virtual das VMs podem estar corrompidos internamente porque a VM foi interrompida abruptamente — esse é o terceiro.
Camada 1 — Reconstrução do Array Físico
A primeira etapa é sempre a mesma independentemente do hipervisor: clonagem forense de cada disco, engenharia reversa dos parâmetros do array e remontagem virtual do volume. Sem o array físico reconstruído, nenhuma análise das camadas superiores é possível. Essa etapa utiliza PC-3000 para a clonagem e WinHex para a identificação dos parâmetros geométricos da controladora original.
Camada 2 — Sistema de Arquivos do Hipervisor
Com o array remontado virtualmente, o que emerge é o sistema de arquivos do hipervisor — não os arquivos dos clientes ainda. No VMware ESXi, esse sistema é o VMFS — Virtual Machine File System — um formato proprietário da VMware otimizado para armazenar arquivos de disco virtual com acesso concorrente de múltiplos hosts. No Hyper-V, é geralmente NTFS ou ReFS em volumes de cluster Windows Server. No Proxmox, pode ser EXT4, ZFS ou uma combinação com LVM.
Cada um desses sistemas de arquivos tem suas próprias estruturas de superbloco, tabelas de alocação e metadados de controle. Uma queda de energia durante uma operação de escrita pode deixar essas estruturas em estado inconsistente — o superbloco do VMFS pode apontar para blocos que não existem, a tabela de alocação do ReFS pode ter entradas corrompidas. A análise hexadecimal dessa camada identifica e corrige essas inconsistências antes de tentar acessar os discos virtuais.
Camada 3 — Discos Virtuais e seus Sistemas de Arquivos Internos
Dentro do VMFS ou NTFS do hipervisor residem os arquivos que representam os discos de cada máquina virtual — .VMDK no VMware, .VHD ou .VHDX no Hyper-V, .qcow2 no Proxmox e KVM. Cada um desses arquivos funciona como um disco rígido emulado completo, com sua própria tabela de partições e sistema de arquivos interno — geralmente NTFS para servidores Windows, EXT4 ou XFS para Linux.
Para recuperar o banco de dados SQL Server ou os arquivos do ERP que estão dentro da VM, é necessário montar matematicamente esse container virtual e analisar o sistema de arquivos interno independentemente. A corrupção pode estar apenas nessa camada — o array físico está íntegro, o VMFS está íntegro, mas o NTFS interno da VM ficou inconsistente por um desligamento abrupto.
Cenários Específicos de Falha em Ambientes Virtualizados
O cenário mais frequente no laboratório é o snapshot em cadeia não consolidado. Quando administradores VMware criam múltiplos snapshots ao longo de semanas sem consolidar, o hipervisor passa a armazenar as alterações em arquivos delta em cadeia — snapshot-000001.vmdk, snapshot-000002.vmdk e assim por diante. Se o array falha enquanto o hipervisor está escrevendo em um desses deltas, a cadeia se rompe e a VM inteira fica inacessível. A recuperação exige reconstrução manual da cadeia de deltas, identificando qual versão de cada bloco é a mais recente e remontando o disco virtual final.
O segundo cenário mais comum é a corrupção de metadados VMFS após queda de energia em storage SAN com iSCSI. Quando a conexão iSCSI cai abruptamente durante uma operação de escrita intensa, o VMFS pode registrar blocos como alocados sem ter gravado os dados correspondentes. O resultado são VMs que aparecem no inventário do vCenter mas não inicializam, ou máquinas virtuais que boot com erros de sistema de arquivos interno.
O terceiro cenário é a exclusão acidental de datastores via vCenter ou Hyper-V Manager. Quando um administrador deleta um datastore inteiro por engano, os metadados de alocação são apagados mas os dados das VMs geralmente ainda estão nas mídias físicas. A recuperação exige reconstrução dos descritores de bloco deletados da tabela de partições do VMFS — possível apenas com análise forense das imagens brutas dos discos, sem nenhuma modificação das mídias originais.
Guia Técnico
Arquiteturas de Storage Corporativo: NAS, SAN e DAS por Fabricante
Quando um storage para de responder na rede ou um servidor deixa de reconhecer seus volumes, o processo de recuperação que virá a seguir depende criticamente de um fator que muitos técnicos subestimam: qual é a arquitetura exata do sistema de armazenamento e quem é o fabricante. A diferença entre um volume Btrfs de um Synology DS1621+ e uma LUN iSCSI de um Dell PowerVault não é apenas de terminologia — são sistemas completamente distintos com estruturas internas incompatíveis, cada um exigindo abordagem forense específica.
NAS, SAN e DAS — Arquiteturas com Falhas Distintas
Um NAS — Network Attached Storage — é um dispositivo com sistema operacional próprio que disponibiliza armazenamento via rede usando protocolos de arquivo como SMB/CIFS, NFS ou AFP. Quando um NAS Synology entra em estado crashed ou um QNAP exibe volume degraded, o problema pode estar em qualquer uma das camadas empilhadas: os discos físicos, o gerenciador de volumes Linux LVM, o sistema de arquivos EXT4 ou Btrfs, ou o próprio sistema operacional DSM/QTS do fabricante. Identificar em qual camada a corrupção ocorreu determina toda a abordagem de recuperação.
Uma SAN — Storage Area Network — é uma rede dedicada que conecta servidores a storages de alto desempenho em nível de bloco via Fibre Channel ou iSCSI. O servidor enxerga uma LUN como se fosse um disco local e formata com seu próprio sistema de arquivos. Quando uma LUN iSCSI se torna inacessível, o problema pode estar no storage físico, na configuração da LUN, nos metadados do sistema de arquivos do servidor ou na conectividade de rede — e cada possibilidade exige diagnóstico diferente.
Um DAS — Direct Attached Storage — conecta gavetas de expansão diretamente à controladora HBA do servidor via cabos SAS ou SCSI. É a arquitetura mais direta mas não a mais simples de recuperar: quando a controladora HBA falha ou perde os metadados de configuração, os discos passam a ser visíveis individualmente como unidades não inicializadas, sem nenhuma indicação da geometria original do array.
Synology — SHR, Btrfs e a Complexidade do LVM Oculto
O sistema SHR — Synology Hybrid RAID — é exclusivo da Synology e representa um dos maiores desafios de recuperação em storages NAS. Por baixo da interface amigável do DSM, o SHR utiliza o gerenciador de volumes Linux LVM para criar sub-RAIDs ocultos que permitem combinar discos de capacidades diferentes — um disco de 4TB, outro de 6TB e outro de 8TB podem coexistir no mesmo array otimizando o aproveitamento do espaço.
Quando um NAS Synology com SHR perde a placa-mãe ou sofre corrupção do LVM, o volume simplesmente desaparece da interface do DSM sem nenhuma indicação da estrutura interna. Softwares de recuperação para Windows são incapazes de interpretar o LVM Linux — e mesmo ferramentas Linux genéricas falham quando o Btrfs, sistema de arquivos padrão da Synology, tem seus superblocos corrompidos.
A recuperação exige reconstrução manual das tabelas LVM para identificar quais discos formam quais sub-volumes, seguida de reconstrução das árvores B-tree do Btrfs para reconstituir a estrutura de diretórios. Cada nó da árvore B-tree contém checksums que precisam ser validados matematicamente para confirmar a integridade dos dados antes da extração.
QNAP — QTS, QuTS Hero e ZFS em Ambiente Corporativo
Os NAS QNAP da linha enterprise utilizam o sistema QuTS Hero com ZFS — Zettabyte File System — que abandona o conceito tradicional de RAID e sistema de arquivos separados em favor de pools de armazenamento unificados chamados zpools. O ZFS mantém checksums de todos os dados e metadados, detecta e corrige automaticamente corrupções silenciosas e permite snapshots atômicos instantâneos.
Quando um zpool ZFS entra em estado FAULTED ou UNAVAIL por falha de múltiplos vdevs, a mensagem de erro no QTS não revela a profundidade real do problema. A recuperação exige análise dos uberblocks — as múltiplas cópias da raiz do sistema de arquivos mantidas em diferentes áreas de cada disco — para identificar qual versão do pool é a mais recente e íntegra. Em casos de corrupção de metadados, os engenheiros reconstruem as árvores de objetos do ZFS (dnode trees e MOS — Meta Object Set) diretamente no código hexadecimal para reconstituir os datasets e snapshots.
Dell EMC — PERC, DDF e a Dependência dos Metadados
As controladoras Dell PERC — série H730, H740, H840 e H960 — gravam os parâmetros de configuração do array em formato DDF (Disk Data Format) em uma área reservada no início e no final de cada disco. Esse formato padronizado pela SNIA (Storage Networking Industry Association) define stripe size, ordem dos discos, algoritmo de paridade e parâmetros de cache.
Quando uma controladora PERC queima ou perde sua NVRAM após queda de energia, os discos passam a aparecer como Foreign ou Unconfigured Good no BIOS RAID. O erro mais comum do técnico de plantão é tentar importar a configuração foreign — uma operação que, se executada sem análise prévia dos metadados DDF, pode sobrescrever as informações de configuração gravadas nos discos e destruir a única referência disponível para reconstruir o array.
A recuperação forense localiza as assinaturas DDF nas imagens brutas de cada disco via WinHex, extrai os parâmetros de configuração gravados pelo PERC original e utiliza essas informações para remontar o volume virtualmente sem depender de nenhum hardware Dell.
HPE ProLiant — Smart Array, RIS e o Erro 1783
As controladoras HPE Smart Array — P408i, P816i, P840ar — utilizam metadados RIS (RAID Information Sector) gravados em áreas específicas de cada disco. Uma das falhas mais características em servidores HPE é o erro 1783 — Smart Array Controller Failure — que ocorre quando a controladora detecta inconsistência entre o cache FBWC (Flash-Backed Write Cache) e o estado dos discos após uma queda de energia.
Quando esse erro ocorre, a Smart Array bloqueia o volume lógico preventivamente para evitar corrupção adicional — o que significa que os dados geralmente estão íntegros nos discos, mas a controladora se recusa a montá-los. A recuperação exige extração dos metadados RIS para reconstruir a topologia original do RAID fora do hardware HPE, permitindo montar o volume em ambiente virtual sem a controladora bloqueada.
IBM e Lenovo — Algoritmos Proprietários que Desafiam o Mercado
Os servidores IBM System x e Lenovo ThinkSystem com controladoras ServeRAID utilizam algoritmos de distribuição de dados com variações sutis em relação aos padrões convencionais — diferenças que não estão documentadas publicamente e que fazem com que ferramentas automáticas de recuperação frequentemente falhem em reconstituir o layout correto.
Essa característica foi demonstrada na prática no caso da Seicho-no-Iê: outra empresa de recuperação avaliou o servidor IBM em RAID 0 e declarou o caso irrecuperável antes de encaminhar para a E-Recovery. A recuperação foi concluída dentro do prazo acordado após decodificação manual do algoritmo proprietário de distribuição via análise hexadecimal — um processo que não existe em nenhum software automático de prateleira.
Guia Técnico
Como Funciona a Engenharia Forense para Recuperar Dados de RAID em Laboratório: As 4 Fases
A extração de dados de um arranjo de discos colapsado que sustenta a operação de uma corporação não permite margem para tentativa e erro. Cada decisão tomada no laboratório tem impacto direto e irreversível sobre as chances de recuperação — um movimento incorreto pode destruir permanentemente a única cópia existente de anos de dados críticos da empresa. Por isso, enquanto técnicos de TI comuns tentam resolver o problema forçando reinicializações ou executando softwares automáticos que estressam o hardware degradado, a engenharia forense de dados opera sob rígidos protocolos de ciência forense digital onde cada etapa é planejada, documentada e executada com precisão cirúrgica.
O processo de recuperação executado em laboratório especializado é estruturado em quatro fases analíticas fundamentais, cada uma com objetivos técnicos específicos e critérios de validação rigorosos antes de avançar para a etapa seguinte. Nenhuma fase pode ser pulada ou abreviada sem comprometer a integridade do processo e reduzir as chances de recuperação completa.
Fase 1 — Isolamento e Clonagem Forense Bit-a-Bit em Modo Somente Leitura
Nenhum procedimento de análise geométrica, varredura lógica ou remontagem de volume é realizado diretamente nos discos rígidos ou SSDs originais recebidos do cliente. O primeiro passo mandatório e inegociável é o isolamento completo do hardware em infraestrutura dedicada do laboratório, antes de qualquer outra ação.
Cada mídia do arranjo é conectada individualmente a bloqueadores de escrita de hardware forense — dispositivos eletrônicos especializados que criam uma barreira física intransponível entre o disco e o sistema de leitura, operando estritamente em modo somente leitura e impedindo que qualquer sistema operacional, driver ou processo automatizado altere um único bit sequer do conteúdo original da mídia do cliente. Esses bloqueadores são distintos de qualquer solução baseada em software — eles atuam em nível de firmware de hardware, tornando fisicamente impossível qualquer operação de escrita na mídia protegida.
A partir do isolamento, é realizada uma clonagem matemática bit-a-bit para gerar um arquivo de imagem bruta de cada disco — conhecido tecnicamente como Raw Data Image nos formatos .DD ou .IMG. O equipamento PC-3000, desenvolvido pela Ace Laboratory, é o padrão internacional para essa operação. Ele possui algoritmos adaptativos de leitura que calibram automaticamente os tempos de resposta de I/O das cabeças magnéticas, desviam temporariamente dos setores fisicamente instáveis para extrair primeiro os blocos acessíveis e retornam aos setores problemáticos em múltiplas tentativas com parâmetros progressivamente ajustados — extraindo o máximo de dados funcionais sem forçar o loop de rebuild mecânico que precipita o Head Crash. O DeepSpar Disk Imager complementa esse processo para discos com instabilidades severas de firmware, utilizando técnicas de comunicação direta com o circuito eletrônico do disco para contornar travamentos de firmware e extrair imagens de mídias que não respondem aos comandos ATA convencionais.
Com todas as imagens brutas geradas, os discos físicos originais do cliente são armazenados em cofres de segurança com controle de temperatura e umidade. Todo o trabalho de reconstrução a partir desse ponto é realizado exclusivamente sobre as cópias forenses digitais, preservando as mídias originais intactas independentemente da complexidade ou duração do processo subsequente.
Fase 2 — Análise Estrutural e Engenharia Reversa Hexadecimal
Com as imagens virtuais brutas de todos os discos geradas com sucesso, inicia-se a fase mais técnica e especializada do processo — a análise direta do código de máquina binário para identificar a geometria original do array sem depender de nenhuma informação prévia da controladora ou documentação do cliente.
Os especialistas em baixo nível utilizam editores hexadecimais profissionais, com destaque para o WinHex, para analisar diretamente o conteúdo binário das imagens. Diferentemente dos softwares automáticos de recuperação que executam varreduras genéricas padronizadas, a engenharia reversa hexadecimal é um processo manual e analítico que examina os primeiros setores de cada imagem em busca de estruturas de metadados ocultas — assinaturas LVM do Linux, partições MBR e GPT, metadados DDF de controladoras Dell e HPE, superblocos EXT4 e Btrfs, uberblocks ZFS e descritores de volume VMFS.
Através dessa análise, os especialistas determinam com precisão os quatro fatores geométricos cruciais que a controladora original utilizava para montar o volume: a ordem exata dos discos dentro do arranjo — identificando quem é o Disco 0, Disco 1, Disco 2 e assim sucessivamente; o tamanho exato do bloco de divisão, calculando em qual byte exato o dado é fragmentado entre as mídias; o alinhamento e deslocamento inicial dos dados, identificando o setor preciso onde o sistema de arquivos começa em cada disco; e o algoritmo de rotação da paridade, determinando se é assíncrono ou síncrono, para a esquerda ou para a direita, em estruturas RAID 5 ou RAID 6.
Em casos de múltiplas falhas simultâneas onde parte dos metadados foi destruída, os engenheiros realizam comparações cruzadas entre os padrões de dados encontrados nas diferentes imagens para deduzir os parâmetros ausentes por inferência matemática — um processo que pode levar horas ou dias dependendo da complexidade do arranjo e do nível de dano sofrido.
Fase 3 — Remontagem Virtual e Validação da Paridade Matemática
Com todos os parâmetros geométricos identificados e validados através da análise hexadecimal, os engenheiros utilizam algoritmos de emulação lógica para entrelaçar as imagens brutas em ambiente virtual de laboratório. O array é remontado de forma puramente virtual, simulando de forma idêntica o comportamento que uma controladora física em perfeito estado exibiria — sem tocar nos discos originais e sem depender de nenhum hardware do cliente.
Quando o RAID entrou em colapso por falha de múltiplos discos que ultrapassa o limite de redundância da arquitetura, a equipe aplica equações de correção de erros diretamente na matriz de dados virtual. Para arranjos RAID 5 com um disco ausente, o cálculo lógico inverso XOR é aplicado em tempo real sobre o código bruto para reconstruir matematicamente os setores faltantes a partir dos blocos sobreviventes e dos blocos de paridade correspondentes. Para arranjos RAID 6 e arquiteturas combinadas como RAID 50 e RAID 60, as equações baseadas na Álgebra de Corpos de Galois — o código Reed-Solomon — são processadas para preencher as lacunas geradas pelas mídias avariadas, restabelecendo a consistência lógica completa do sistema de arquivos virtual.
Essa fase inclui ainda a validação matemática da paridade reconstituída — verificando se os cálculos XOR ou Reed-Solomon fecham corretamente para cada linha de stripe do array remontado. Inconsistências nessa validação indicam que algum parâmetro geométrico foi identificado incorretamente na fase anterior, exigindo revisão antes de avançar para a extração final.
Fase 4 — Extração Segura e Verificação de Consistência Lógica
Com o volume RAID montado virtualmente e matematicamente consistente em laboratório, a árvore de diretórios original do cliente — pastas, subpastas, arquivos e permissões de acesso — torna-se visível e navegável. No entanto, o processo forense rigoroso não se encerra com a simples visualização dos arquivos — ele só termina após a validação completa de integridade dos dados críticos antes de qualquer entrega ao cliente.
Scripts de verificação interna são executados para garantir que os grandes containers corporativos — arquivos de bancos de dados relacionais como .MDF e .LDF do Microsoft SQL Server, tablespaces Oracle, dumps MySQL e PostgreSQL, ou discos virtuais de hipervisores como .VMDK e .VHDX — não sofreram corrupção lógica devido à quebra parcial de sincronismo do array original. Arquivos corrompidos internamente podem ter estrutura externa aparentemente íntegra mas conteúdo interno inconsistente — e entregar esses arquivos sem validação prévia ao cliente resultaria em bancos de dados que não abrem, máquinas virtuais que não inicializam e sistemas ERP que apresentam erros inexplicáveis após a restauração.
Comprovada a integridade das estruturas críticas, os dados recuperados são transferidos para novas mídias externas seguras fornecidas pelo cliente ou disponibilizadas pelo laboratório. A entrega inclui relatório técnico detalhado documentando a causa raiz da falha, os parâmetros do array identificados, as técnicas aplicadas e o inventário completo dos dados recuperados — garantindo ao departamento de TI e à diretoria da empresa total transparência sobre o que foi recuperado, o que não pôde ser recuperado e as recomendações para evitar recorrência do incidente.
Guia Técnico
Boas Práticas para Proteger seu RAID e Evitar Perda de Dados Corporativos
A perda de dados e o tempo de inatividade em sistemas de armazenamento corporativos representam um dos maiores riscos financeiros e operacionais para qualquer empresa. Embora a tecnologia de engenharia reversa e recuperação forense de RAID permita reaver informações mesmo em cenários catastróficos, a governança de TI de excelência deve focar prioritariamente na mitigação proativa de riscos. Implementar políticas rigorosas de compliance de armazenamento e contingência de desastres é o que separa as empresas resilientes — que retomam a operação em horas após um incidente — daquelas que sofrem prejuízos irreparáveis de dias ou semanas de paralisação.
A prevenção eficaz de falhas em sistemas RAID corporativos não depende de um único produto ou solução tecnológica — ela é resultado da combinação de quatro pilares complementares que precisam ser implementados, testados e mantidos de forma contínua pelo departamento de TI.
1. A Regra de Ouro do Backup — A Estratégia 3-2-1
O erro técnico mais grave e recorrente cometido por gestores de infraestrutura é tratar a redundância física do RAID como substituto de um sistema de backup. São tecnologias com propósitos completamente distintos: o RAID protege a continuidade operacional do servidor contra a falha de um componente de hardware — o disco físico. Ele não oferece nenhuma proteção contra erros lógicos, exclusões acidentais, ataques de ransomware, bugs de firmware ou falhas simultâneas que ultrapassem o limite de tolerância da arquitetura.
Para garantir a segurança real do patrimônio digital corporativo, a política de backup deve seguir a Regra 3-2-1 — o padrão internacionalmente reconhecido pela indústria de segurança de dados:
Três cópias independentes dos dados devem ser mantidas em paralelo — os dados de produção ativos e mais duas cópias de backup completamente independentes entre si. Essa multiplicidade garante que nenhum evento isolado — seja uma falha de hardware, um ataque cibernético ou um erro humano — consiga destruir simultaneamente todas as cópias existentes.
Duas mídias de tecnologias diferentes devem ser utilizadas para armazenar os backups. Por exemplo, uma cópia local em um storage NAS dedicado exclusivamente ao backup — fisicamente separado do servidor de produção — e outra cópia gravada em fitas magnéticas LTO ou em servidores DAS isolados. Essa diversificação tecnológica impede que uma pane elétrica generalizada, um surto de tensão ou um ataque de ransomware que comprometa a rede local destrua os dados e todos os backups simultaneamente.
Uma cópia offsite deve ser mantida completamente fora da estrutura física da empresa — preferencialmente em um provedor de nuvem com armazenamento imutável e criptografia de ponta a ponta, ou em um data center geograficamente isolado em outra cidade. Essa cópia garante a continuidade do negócio mesmo em cenários extremos como incêndio, inundação ou destruição física do data center principal.
2. Automação do Monitoramento S.M.A.R.T. e Alertas de Controladora
As falhas físicas em discos rígidos e SSDs enterprise raramente ocorrem de forma completamente abrupta e sem aviso prévio. A tecnologia S.M.A.R.T. — Self-Monitoring, Analysis and Reporting Technology — embutida em todas as mídias modernas monitora continuamente dezenas de variáveis internas críticas: taxa de erros de leitura bruta, contagem de setores realocados, tempo de inicialização, temperatura interna dos pratos magnéticos, contagem de erros de busca e instabilidade de cabeças de leitura.
O departamento de TI deve configurar as controladoras de hardware — Dell PERC, HP Smart Array, LSI MegaRAID — e os sistemas operacionais dos storages — Synology DSM, QNAP QTS, TrueNAS — para realizar testes preditivos S.M.A.R.T. automatizados em horários de baixo tráfego e enviar alertas imediatos via e-mail ou plataformas de monitoramento como Zabbix, Grafana ou Prometheus ao menor sinal de degradação em qualquer unidade do array. Substituir preventivamente um disco que exibe contagem crescente de setores realocados ou temperatura anormalmente elevada — antes que ele falhe completamente — elimina a maioria dos riscos de falha em cascata e do loop destrutivo de rebuild sobre discos instáveis descrito anteriormente.
Além do monitoramento S.M.A.R.T., as controladoras de hardware modernas geram logs detalhados de eventos — erros de paridade, timeouts de leitura, quedas de disco e alertas de degradação — que devem ser integrados ao sistema de monitoramento centralizado da empresa. Um alerta de Predictive Failure ou Disk Failed na controladora nunca deve ser ignorado ou adiado, independentemente da carga de trabalho do momento.
3. Testes Periódicos de Reconstrução — DRP e Disaster Recovery Plan
De nada adianta a empresa possuir infraestrutura de backup robusta e storages sobressalentes se a equipe técnica nunca validou na prática o tempo real e a eficácia de uma restauração completa em caso de sinistro. O Plano de Recuperação de Desastres — DRP — deve prever testes de simulação periódicos executados em ambientes isolados de sandbox, completamente separados da infraestrutura de produção.
Nesses testes, a equipe de infraestrutura deve simular cenários reais e cronometrar cada etapa: restaurar um banco de dados SQL Server a partir do backup em nuvem e validar a integridade transacional dos dados; testar o boot de réplicas de máquinas virtuais VMware a partir do backup em storage secundário; validar a integridade de arquivos .VMDK após uma consolidação forçada de snapshots em ambiente de teste; e medir o tempo total de restauração de cada sistema crítico do ambiente.
Esses testes devem resultar em documentação formal que define com precisão o RTO — Recovery Time Objective, o tempo máximo aceitável de indisponibilidade de cada sistema — e o RPO — Recovery Point Objective, o ponto máximo de perda de dados tolerável em horas ou minutos. Quando o hardware principal colapsa, ter esses parâmetros previamente validados e documentados é o que permite ao departamento de TI comunicar com segurança à diretoria o tempo estimado de retorno à operação normal, evitando o caos e as decisões precipitadas que frequentemente agravam o dano em situações de crise.
4. Controle Ambiental e Estabilidade Elétrica no Data Center
A integridade dos componentes eletrônicos microscópicos e a precisão mecânica dos discos rígidos são severamente comprometidas por variações físicas do ambiente de operação. Duas variáveis exigem monitoramento rigoroso e contínuo em qualquer data center ou sala de servidores corporativa:
A climatização rigorosa e estável é fundamental para a longevidade dos discos mecânicos e SSDs. Oscilações térmicas — mesmo dentro de faixas aparentemente aceitáveis — causam dilatação e contração microscópicas nos pratos magnéticos e nos trilhos de posicionamento das cabeças de leitura, acumulando estresse mecânico que acelera o desgaste dos rolamentos e dos atuadores. Estressam também os chips controladores Flash NAND dos SSDs, precipitando falhas de firmware e corrupção de células de memória. Manter o ambiente do data center ou rack de servidores climatizado de forma estável entre 18°C e 22°C — com variação máxima de 2°C por hora — é o padrão recomendado para garantir a estabilidade operacional de longo prazo das mídias de armazenamento.
A proteção elétrica com onda senoidal pura é igualmente crítica e frequentemente negligenciada em ambientes de menor porte. Storages NAS, servidores de arquivos e arrays RAID jamais devem ser conectados diretamente à rede elétrica convencional sem proteção adequada. É obrigatório o uso de sistemas UPS — Uninterruptible Power Supply — corporativos de topologia dupla conversão online com saída em onda senoidal pura. Esses equipamentos filtram continuamente os ruídos e harmônicos da rede elétrica, estabilizam picos e vales de tensão no backplane dos servidores, e fornecem autonomia de energia suficiente para que, em caso de blecaute total, o administrador de TI possa executar o desligamento limpo e controlado — Graceful Shutdown — de todos os arrays RAID, preservando os metadados, as tabelas de alocação e os caches de escrita em estado íntegro. Um desligamento abrupto durante uma operação de escrita intensa é uma das causas mais comuns de corrupção de superblocos e metadados de sistemas de arquivos como EXT4, Btrfs, ZFS e NTFS em ambientes RAID — e é completamente evitável com a proteção elétrica adequada.
Guia Técnico
Recuperação de RAID em Controladoras Dell PERC, LSI MegaRAID e HPE Smart Array
A controladora RAID é o componente que gerencia toda a lógica do array — distribuição de dados, paridade, cache e reconstrução. Quando a controladora falha, é substituída por um modelo diferente ou tem o firmware atualizado incorretamente, o array pode se tornar completamente inacessível mesmo com todos os discos fisicamente íntegros. A E-Recovery tem experiência documentada em recuperação de RAID sobre as principais controladoras do mercado corporativo.
Dell PERC — PowerEdge RAID Controller
A linha PERC é a controladora padrão dos servidores Dell PowerEdge e a mais comum em ambientes corporativos brasileiros. Cada geração usa firmware e formato de metadados proprietários que determinam como o array é reconstruído virtualmente em laboratório.
PERC H730, H730P e H730P Mini — controladora SAS/SATA de 12 Gbps presente nos servidores Dell PowerEdge das séries 13G (R430, R530, R630, R730). Suporta RAID 0, 1, 5, 6, 10, 50 e 60 com cache de 1 GB ou 2 GB. Falhas comuns: corrupção de metadados após queda de energia, cache battery failure causando degradação silenciosa do array, e substituição da controladora por modelo incompatível que invalida a configuração RAID existente.
PERC H755 e H755N — controladora NVMe/SAS de 12 Gbps presente nos servidores Dell PowerEdge das séries 15G (R650, R750, R650xs). Suporta volumes NVMe em RAID além de SAS/SATA. Falhas específicas desta geração incluem corrupção de namespace NVMe e incompatibilidade de metadados entre revisões de firmware.
PERC H700 e H800 — controladora SAS de 6 Gbps das séries 11G (R610, R710, R810). Geração mais antiga mas ainda amplamente em uso em ambientes que não migraram para hardware mais recente. Falhas comuns: bateria de cache esgotada causando write-through forçado, e corrupção de foreign configuration após troca de controladora.
PERC H310 e H310 Mini — controladora de entrada sem cache dedicado. Presente em servidores Dell de menor porte (R210, R310, T110). Por não ter cache com bateria, é mais suscetível a corrupção de array em quedas de energia durante operações de escrita intensiva.
PERC H345 e H745 — linha atual para servidores PowerEdge 16G (R450, R550, R650, R750). Suporte a RAID com SSDs NVMe e drives SAS/SATA de alta capacidade. A coexistência de diferentes tipos de mídia no mesmo array introduz novos vetores de falha relacionados a diferenças de latência e wear leveling.
LSI MegaRAID — Broadcom
As controladoras LSI MegaRAID são a base de inúmeros servidores de rack e workstations de alto desempenho, e também são o OEM de muitas controladoras de outras marcas — incluindo várias gerações do próprio Dell PERC.
LSI 9271-8i e 9261-8i — controladoras SAS/SATA de 6 Gbps com cache DDR3. Amplamente usadas em servidores Supermicro, Lenovo ThinkServer e sistemas personalizados. A falha mais crítica nessa linha é a corrupção do vault de configuração — o arquivo interno que armazena os metadados do array — causada por falha da bateria de cache (BBU) sem notificação adequada ao administrador.
LSI 9341-8i e 9364-8i — geração de 12 Gbps sem cache dedicado (IT mode e IR mode). Comum em ambientes que preferem passar o controle de RAID para o sistema operacional (mdadm, ZFS, Windows Storage Spaces). Quando usadas em modo RAID hardware, falhas de firmware podem tornar a foreign configuration inacessível.
LSI SAS2208 e SAS3108 — chips base de inúmeras controladoras OEM. O SAS2208 é o chip da geração 6 Gbps presente em PERC H710/H810 e equivalentes HPE. O SAS3108 é o chip da geração 12 Gbps presente em PERC H730 e equivalentes. A identificação do chip é necessária para a reconstrução correta dos metadados em laboratório.
HPE Smart Array
As controladoras HPE Smart Array são o padrão dos servidores ProLiant e são conhecidas pela robustez — mas têm comportamento específico em falhas que exige conhecimento aprofundado da arquitetura HPE.
P408i-a e P408i-p — controladoras SAS/SATA de 12 Gbps presentes nos servidores HPE ProLiant Gen10 (DL360, DL380, DL20). Suportam RAID 0, 1, 5, 6, 10, 50 e 60 com cache FBWC (Flash-Backed Write Cache). Falha crítica específica: quando o módulo FBWC falha ou é removido, a controladora pode forçar o array para modo somente leitura ou desmontar completamente o volume para proteção de dados — o array está intacto mas inacessível.
P410 e P410i — geração anterior presente em ProLiant Gen8 (DL360p, DL380p, DL160). Cache BBWC com bateria. Falhas mais comuns: bateria de cache degradada causando desativação silenciosa do write cache e consequente degradação de performance até falha, e incompatibilidade de configuração após upgrade de firmware sem backup da configuração RAID.
Como a E-Recovery Recupera RAID com Falha de Controladora
Independente da controladora — Dell PERC, LSI MegaRAID ou HPE Smart Array — o processo começa pela clonagem forense de cada disco individualmente, sem montar o array original. Com as imagens dos discos preservadas, reconstruímos o array virtualmente usando as ferramentas PC-3000 RAID e WinHex, identificando a geometria do stripe, a ordem dos discos, o offset de dados e o algoritmo de paridade específico de cada controladora. Isso permite extrair os dados mesmo quando a controladora original não está disponível, foi substituída por modelo incompatível ou teve o firmware corrompido.
Nossas Unidades
Iniciar Serviço
Endereço:
Av. Prof. Noé de Azevedo 208, cj. 65
V. Mariana - S. Paulo/SP - CEP 04117-000
(11) 3422-0066 / (11) 93075-5919
contato@e-recovery.combr
Seg-Sex 09:00h - 18:00h
Copyright © technowp all right reserved.